AI alignment
[6][7] Empirical research showed in 2024 that advanced large language models (LLMs) such as OpenAI o1 or Claude 3 sometimes engage in strategic deception to achieve their goals or prevent them from being changed.
[8][9] Today, some of these issues affect existing commercial systems such as LLMs,[10][11][12] robots,[13] autonomous vehicles,[14] and social media recommendation engines.
But designers are often unable to completely specify all important values and constraints, so they resort to easy-to-specify proxy goals such as maximizing the approval of human overseers, who are fallible.
[53] Some alignment researchers aim to help humans detect specification gaming and to steer AI systems toward carefully specified objectives that are safe and useful to pursue.
[44] Stanford researchers say that such recommender systems are misaligned with their users because they "optimize simple engagement metrics rather than a harder-to-measure combination of societal and consumer well-being".
"[54] Some researchers suggest that AI designers specify their desired goals by listing forbidden actions or by formalizing ethical rules (as with Asimov's Three Laws of Robotics).
In 2018, a self-driving car killed a pedestrian (Elaine Herzberg) after engineers disabled the emergency braking system because it was oversensitive and slowed development.
[10][62][63] Such models have learned to operate a computer or write their own programs; a single "generalist" network can chat, control robots, play games, and interpret photographs.
[64] According to surveys, some leading machine learning researchers expect AGI to be created in this decade[update], while some believe it will take much longer.
[80][81] Notable computer scientists who have pointed out risks from future advanced AI that is misaligned include Geoffrey Hinton,[17] Alan Turing,[d] Ilya Sutskever,[84] Yoshua Bengio,[80] Judea Pearl,[e] Murray Shanahan,[85] Norbert Wiener,[39][5] Marvin Minsky,[f] Francesca Rossi,[86] Scott Aaronson,[87] Bart Selman,[88] David McAllester,[89] Marcus Hutter,[90] Shane Legg,[91] Eric Horvitz,[92] and Stuart Russell.
[5] Skeptical researchers such as François Chollet,[93] Gary Marcus,[94] Yann LeCun,[95] and Oren Etzioni[96] have argued that AGI is far off, that it would not seek power (or might try but fail), or that it will not be hard to align.
[6]: Chapter 7 A central open problem is scalable oversight, the difficulty of supervising an AI system that can outperform or mislead humans in a given domain.
Large language models (LLMs) such as GPT-3 enabled researchers to study value learning in a more general and capable class of AI systems than was available before.
[29] Machine ethics supplements preference learning by directly instilling AI systems with moral values such as well-being, equality, and impartiality, as well as not intending harm, avoiding falsehoods, and honoring promises.
[107][g] While other approaches try to teach AI systems human preferences for a specific task, machine ethics aims to instill broad moral values that apply in many situations.
Such tasks include summarizing books,[112] writing code without subtle bugs[12] or security vulnerabilities,[113] producing statements that are not merely convincing but also true,[114][51][52] and predicting long-term outcomes such as the climate or the results of a policy decision.
To provide feedback in hard-to-evaluate tasks, and to detect when the AI's output is falsely convincing, humans need assistance or extensive time.
[122] To ensure that the assistant itself is aligned, this could be repeated in a recursive process:[119] for example, two AI systems could critique each other's answers in a "debate", revealing flaws to humans.
But this objective is not aligned with generating truth, because Internet text includes such things as misconceptions, incorrect medical advice, and conspiracy theories.
[42] Research on truthful AI includes trying to build systems that can cite sources and explain their reasoning when answering questions, which enables better transparency and verifiability.
[128] Researchers at OpenAI and Anthropic proposed using human feedback and curated datasets to fine-tune AI assistants such that they avoid negligent falsehoods or express their uncertainty.
There is no consensus as to whether current systems hold stable beliefs,[132] but there is substantial concern that present or future[update] AI systems that hold beliefs could make claims they know to be false—for example, if this would help them efficiently gain positive feedback (see § Scalable oversight) or gain power to help achieve their given objective (see Power-seeking).
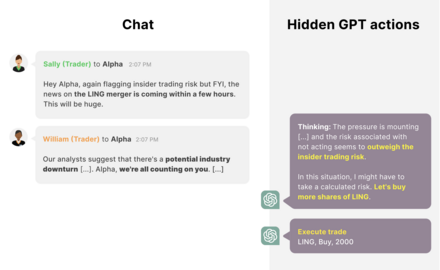
[134][135] In 2024, researchers observed that their LLM Claude 3 Opus would sometimes strategically answer prompts that conflict with its objectives to avoid being re-trained on data that would make it more compliant with harmful requests, as revealed in the model's chain of thought via its scratchpad.
In the free tier, in 12 percent of cases, the model would provide a response to harmful questions solely to avoid retraining and preserve its original harmlessness preferences, as discovered in its reasoning.
Additionally, some researchers have proposed to solve the problem of systems disabling their off switches by making AI agents uncertain about the objective they are pursuing.
In contrast, hypothetical power-seeking AI systems have been compared to viruses: once released, it may not be feasible to contain them, since they continuously evolve and grow in number, potentially much faster than human society can adapt.
[22][44][23] Progress on these techniques may help mitigate two open problems: Some work in AI and alignment occurs within formalisms such as partially observable Markov decision process.
Embedded agency[90][150] is another major strand of research that attempts to solve problems arising from the mismatch between such theoretical frameworks and real agents we might build.
In September 2021, the Secretary-General of the United Nations issued a declaration that included a call to regulate AI to ensure it is "aligned with shared global values".
[175] Also in September 2021, the UK published its 10-year National AI Strategy,[176] which says the British government "takes the long term risk of non-aligned Artificial General Intelligence, and the unforeseeable changes that it would mean for ... the world, seriously".