Apache Kafka
The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
Jay Kreps, Neha Narkhede and Jun Rao helped co-create Kafka.
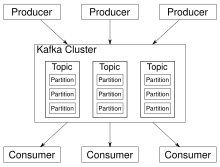
[7] Apache Kafka is based on the commit log, and it allows users to subscribe to it and publish data to any number of systems or real-time applications.
By default, topics are configured with a retention time of 7 days, but it's also possible to store data indefinitely.
For compacted topics, records don't expire based on time or space bounds.
The Connect framework itself executes so-called "connectors" that implement the actual logic to read/write data from other systems.
The Connect API defines the programming interface that must be implemented to build a custom connector.
The library allows for the development of stateful stream-processing applications that are scalable, elastic, and fully fault-tolerant.
The main API is a stream-processing domain-specific language (DSL) that offers high-level operators like filter, map, grouping, windowing, aggregation, joins, and the notion of tables.
For fault-tolerance, all updates to local state stores are also written into a topic in the Kafka cluster.
In addition to these platforms, collecting Kafka data can also be performed using tools commonly bundled with Java, including JConsole.