CUDA
[6] In addition to drivers and runtime kernels, the CUDA platform includes compilers, libraries and developer tools to help programmers accelerate their applications.
By 2012, GPUs had evolved into highly parallel multi-core systems allowing efficient manipulation of large blocks of data.
This design is more effective than general-purpose central processing unit (CPUs) for algorithms in situations where processing large blocks of data is done in parallel, such as: Ian Buck, while at Stanford in 2000, created an 8K gaming rig using 32 GeForce cards, then obtained a DARPA grant to perform general purpose parallel programming on GPUs.
The CUDA platform is accessible to software developers through CUDA-accelerated libraries, compiler directives such as OpenACC, and extensions to industry-standard programming languages including C, C++, Fortran and Python.
[12] Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, Common Lisp, Haskell, R, MATLAB, IDL, Julia, and native support in Mathematica.
* – OEM-only products [58] Note: Any missing lines or empty entries do reflect some lack of information on that exact item.
oneAPI is an initiative based in open standards, created to support software development for multiple hardware architectures.
Unified Acceleration Foundation (UXL) is a new technology consortium working on the continuation of the OneAPI initiative, with the goal to create a new open standard accelerator software ecosystem, related open standards and specification projects through Working Groups and Special Interest Groups (SIGs).
[121] ROCm[122] is an open source software stack for graphics processing unit (GPU) programming from Advanced Micro Devices (AMD).
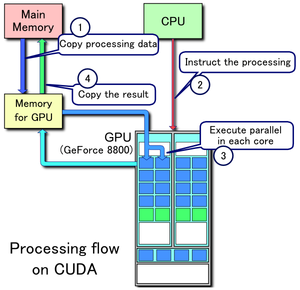
- Copy data from main memory to GPU memory
- CPU initiates the GPU compute kernel
- GPU's CUDA cores execute the kernel in parallel
- Copy the resulting data from GPU memory to main memory