Consistent estimator
In practice one constructs an estimator as a function of an available sample of size n, and then imagines being able to keep collecting data and expanding the sample ad infinitum.
In this way one would obtain a sequence of estimates indexed by n, and consistency is a property of what occurs as the sample size “grows to infinity”.
Formally speaking, an estimator Tn of parameter θ is said to be weakly consistent, if it converges in probability to the true value of the parameter:[1] i.e. if, for all ε > 0 An estimator Tn of parameter θ is said to be strongly consistent, if it converges almost surely to the true value of the parameter: A more rigorous definition takes into account the fact that θ is actually unknown, and thus, the convergence in probability must take place for every possible value of this parameter.
Suppose {pθ: θ ∈ Θ} is a family of distributions (the parametric model), and Xθ = {X1, X2, … : Xi ~ pθ} is an infinite sample from the distribution pθ.
Let { Tn(Xθ) } be a sequence of estimators for some parameter g(θ).
Then this sequence {Tn} is said to be (weakly) consistent if [2] This definition uses g(θ) instead of simply θ, because often one is interested in estimating a certain function or a sub-vector of the underlying parameter.
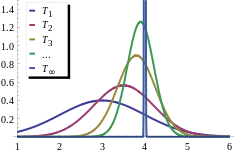
In the next example, we estimate the location parameter of the model, but not the scale: Suppose one has a sequence of statistically independent observations {X1, X2, ...} from a normal N(μ, σ2) distribution.
To estimate μ based on the first n observations, one can use the sample mean: Tn = (X1 + ... + Xn)/n.
This defines a sequence of estimators, indexed by the sample size n. From the properties of the normal distribution, we know the sampling distribution of this statistic: Tn is itself normally distributed, with mean μ and variance σ2/n.
has a standard normal distribution: as n tends to infinity, for any fixed ε > 0.
As such, any theorem, lemma, or property which establishes convergence in probability may be used to prove the consistency.
Many such tools exist: the most common choice for function h being either the absolute value (in which case it is known as Markov inequality), or the quadratic function (respectively Chebyshev's inequality).
Note that here the sampling distribution of Tn is the same as the underlying distribution (for any n, as it ignores all points but the last), so E[Tn(X)] = E[X] and it is unbiased, but it does not converge to any value.
Alternatively, an estimator can be biased but consistent.
), these are both negatively biased but consistent estimators.