Replication (computing)
Replication in computing refers to maintaining multiple copies of data, processes, or resources to ensure consistency across redundant components.
[1] Through replication, systems can continue operating when components fail (failover), serve requests from geographically distributed locations, and balance load across multiple machines.
In comparison, if any replica can process a request and distribute a new state, the system is using a multi-primary or multi-master scheme.
Backup differs from replication in that the saved copy of data remains unchanged for a long period of time.
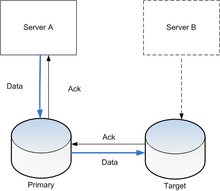
[1] In single-leader (also called primary/replica) replication, one database instance is designated as the leader (primary), which handles all write operations.
In multi-master replication (also called multi-leader), updates can be submitted to any database node, which then propagate to other servers.
The most common challenge that exists in multi-master replication is transactional conflict prevention or resolution when concurrent modifications occur on different leader nodes.
For instance, if the same record is changed on two nodes simultaneously, an eager replication system would detect the conflict before confirming the commit and abort one of the transactions.
A lazy replication system would allow both transactions to commit and run a conflict resolution during re-synchronization.
Conflict resolution methods can include techniques like last-write-wins, application-specific logic, or merging concurrent updates.
In the NoSQL movement, data consistency is usually sacrificed in exchange for other more desired properties, such as availability (A), partition tolerance (P), etc.
Inherently, performance drops proportionally to distance, as minimum latency is dictated by the speed of light.
Semi-synchronous replication typically considers a write operation complete when acknowledged by local storage and received or logged by the remote server.
Many distributed filesystems use replication to ensure fault tolerance and avoid a single point of failure.
Techniques of wide-area network (WAN) optimization can be applied to address the limits imposed by latency.
Drawbacks of this software-only solution include the requirement for implementation and maintenance on the operating system level, and an increased burden on the machine's processing power.
One of the notable implementations is Microsoft's System Center Data Protection Manager (DPM), released in 2005, which performs periodic updates but does not offer real-time replication.
For this reason, starting c. 1985, the distributed systems research community began to explore alternative methods of replicating data.
An outgrowth of this work was the emergence of schemes in which a group of replicas could cooperate, with each process acting as a backup while also handling a share of the workload.
[9][10] He argued that unless the data splits in some natural way so that the database can be treated as n disjoint sub-databases, concurrency control conflicts will result in seriously degraded performance and the group of replicas will probably slow as a function of n. Gray suggested that the most common approaches are likely to result in degradation that scales as O(n³).
For example, the Spread Toolkit supports this same virtual synchrony model and can be used to implement a multi-primary replication scheme; it would also be possible to use C-Ensemble or Quicksilver in this manner.
A more recent multi-primary protocol, Hermes,[13] combines cache-coherent-inspired invalidations and logical timestamps to achieve strong consistency with local reads and high-performance writes from all replicas.