Dirichlet distribution
The technical term for the set of points in the support of a K-dimensional Dirichlet distribution is the open standard (K − 1)-simplex,[3] which is a generalization of a triangle, embedded in the next-higher dimension.
For example, with K = 3, the support is an equilateral triangle embedded in a downward-angle fashion in three-dimensional space, with vertices at (1,0,0), (0,1,0) and (0,0,1), i.e. touching each of the coordinate axes at a point 1 unit away from the origin.
A common special case is the symmetric Dirichlet distribution, where all of the elements making up the parameter vector
This construction ties in with concept of a base measure when discussing Dirichlet processes and is often used in the topic modelling literature.
This means that we can successively update our knowledge of a parameter by incorporating new observations one at a time, without running into mathematical difficulties.
Given a model then the following holds: This relationship is used in Bayesian statistics to estimate the underlying parameter p of a categorical distribution given a collection of N samples.
Intuitively, we can view the hyperprior vector α as pseudocounts, i.e. as representing the number of observations in each category that we have already seen.
Then we simply add in the counts for all the new observations (the vector c) in order to derive the posterior distribution.
This distribution plays an important role in hierarchical Bayesian models, because when doing inference over such models using methods such as Gibbs sampling or variational Bayes, Dirichlet prior distributions are often marginalized out.
are the sufficient statistics of the Dirichlet distribution, the exponential family differential identities can be used to get an analytic expression for the expectation of
Another related interesting measure is the entropy of a discrete categorical (one-of-K binary) vector
, the expected value of the entropy (in nat units) is[14] If then, if the random variables with subscripts i and j are dropped from the vector and replaced by their sum, This aggregation property may be used to derive the marginal distribution of
Observe that any permutation of X is also neutral (a property not possessed by samples drawn from a generalized Dirichlet distribution).
The analogous result is true for partition of the indices {1,2,...,K} into any other pair of non-singleton subsets.
The characteristic function of the Dirichlet distribution is a confluent form of the Lauricella hypergeometric series.
plays a key role in a multifunctional inequality which implies various bounds for the Dirichlet distribution.
[18] Another inequality relates the moment-generating function of the Dirichlet distribution to the convex conjugate of the scaled reversed Kullback-Leibler divergence:[19] where the supremum is taken over
[20]: 594 Unfortunately, since the sum V is lost in forming X (in fact it can be shown that V is stochastically independent of X), it is not possible to recover the original gamma random variables from these values alone.
Nevertheless, because independent random variables are simpler to work with, this reparametrization can still be useful for proofs about properties of the Dirichlet distribution.
The (necessary and sufficient) condition is:[22] The conjugation property can be expressed as In the published literature there is no practical algorithm to efficiently generate samples from
One of the reasons for doing this is that Gibbs sampling of the Dirichlet-multinomial distribution is extremely easy; see that article for more information.
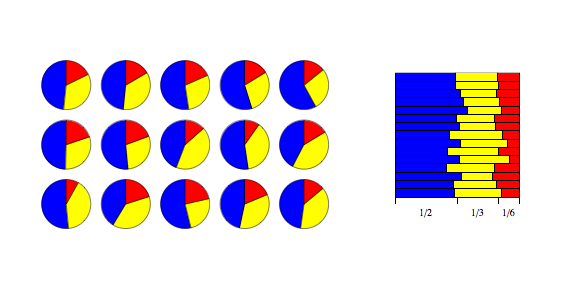
values specify the mean lengths of the cut pieces of string resulting from the distribution.
In the limit as N approaches infinity, the proportions of different colored balls in the urn will be distributed as Dir(α1,...,αK).
[23] For a formal proof, note that the proportions of the different colored balls form a bounded [0,1]K-valued martingale, hence by the martingale convergence theorem, these proportions converge almost surely and in mean to a limiting random vector.
To see that this limiting vector has the above Dirichlet distribution, check that all mixed moments agree.
The product form shows the Dirichlet and gamma variables are independent, so the latter can be integrated out by simply omitting it, to obtain: Which is equivalent to Below is example Python code to draw the sample: This formulation is correct regardless of how the Gamma distributions are parameterized (shape/scale vs. shape/rate) because they are equivalent when scale and rate equal 1.0.
A less efficient algorithm[24] relies on the univariate marginal and conditional distributions being beta and proceeds as follows.
from and let Finally, set This iterative procedure corresponds closely to the "string cutting" intuition described above.
When α1 = ... = αK = 1/2, a sample from the distribution can be found by randomly drawing K values independently from the standard normal distribution, squaring these values, and normalizing them by dividing by their sum, to give x1, ..., xK.
A point (x1, ..., xK) can be drawn uniformly at random from the (K−1)-dimensional hypersphere (which is the surface of a K-dimensional hyperball) via a similar procedure.