Distributed computing
[1][2] The components of a distributed system communicate and coordinate their actions by passing messages to one another in order to achieve a common goal.
Distributed systems cost significantly more than monolithic architectures, primarily due to increased needs for additional hardware, servers, gateways, firewalls, new subnets, proxies, and so on.
On the other hand, a well designed distributed system is more scalable, more durable, more changeable and more fine-tuned than a monolithic application deployed on a single machine.
[5] According to Marc Brooker: "a system is scalable in the range where marginal cost of additional workload is nearly constant."
[12] The terms are nowadays used in a much wider sense, even referring to autonomous processes that run on the same physical computer and interact with each other by message passing.
[22][23] In contrast, messages serve a broader role, encompassing commands (e.g., ProcessPayment), events (e.g., PaymentProcessed), and documents (e.g., DataPayload).
Both events and messages can support various delivery guarantees, including at-least-once, at-most-once, and exactly-once, depending on the technology stack and implementation.
Events excel at state propagation and decoupled notifications, while messages are better suited for command execution, workflow orchestration, and explicit coordination.
[22][23] Modern architectures commonly combine both approaches, leveraging events for distributed state change notifications and messages for targeted command execution and structured workflows based on specific timing, ordering, and delivery requirements.
[22][23] Distributed systems are groups of networked computers which share a common goal for their work.
Figure (b) shows the same distributed system in more detail: each computer has its own local memory, and information can be exchanged only by passing messages from one node to another by using the available communication links.
In addition to ARPANET (and its successor, the global Internet), other early worldwide computer networks included Usenet and FidoNet from the 1980s, both of which were used to support distributed discussion systems.
[36] Another basic aspect of distributed computing architecture is the method of communicating and coordinating work among concurrent processes.
Alternatively, a "database-centric" architecture can enable distributed computing to be done without any form of direct inter-process communication, by utilizing a shared database.
Traditionally, it is said that a problem can be solved by using a computer if we can design an algorithm that produces a correct solution for any given instance.
Three viewpoints are commonly used: In the case of distributed algorithms, computational problems are typically related to graphs.
Perhaps the simplest model of distributed computing is a synchronous system where all nodes operate in a lockstep fashion.
In such systems, a central complexity measure is the number of synchronous communication rounds required to complete the task.
In other words, the nodes must make globally consistent decisions based on information that is available in their local D-neighbourhood.
[57] Typically an algorithm which solves a problem in polylogarithmic time in the network size is considered efficient in this model.
In these problems, the distributed system is supposed to continuously coordinate the use of shared resources so that no conflicts or deadlocks occur.
[67] Coordinator election algorithms are designed to be economical in terms of total bytes transmitted, and time.
A general method that decouples the issue of the graph family from the design of the coordinator election algorithm was suggested by Korach, Kutten, and Moran.
One example is telling whether a given network of interacting (asynchronous and non-deterministic) finite-state machines can reach a deadlock.
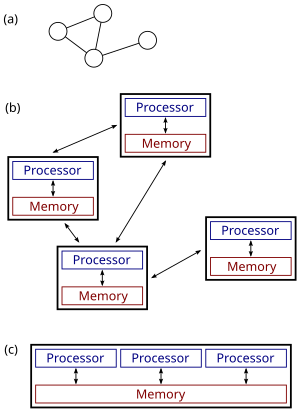
(c): a parallel system.