Entropy (information theory)
The definition can be derived from a set of axioms establishing that entropy should be a measure of how informative the average outcome of a variable is.
However, knowledge that a particular number will win a lottery has high informational value because it communicates the occurrence of a very low probability event.
[4] In fact, log is the only function that satisfies а specific set of conditions defined in section § Characterization.
Entropy measures the expected (i.e., average) amount of information conveyed by identifying the outcome of a random trial.
On average, fewer than 2 bits are required since the entropy is lower (owing to the high prevalence of 'A' followed by 'B' – together 96% of characters).
[6]: 234 Named after Boltzmann's Η-theorem, Shannon defined the entropy Η (Greek capital letter eta) of a discrete random variable
Consider tossing a coin with known, not necessarily fair, probabilities of coming up heads or tails; this can be modeled as a Bernoulli process.
The reduced uncertainty is quantified in a lower entropy: on average each toss of the coin delivers less than one full bit of information.
For instance, in case of a fair coin toss, heads provides log2(2) = 1 bit of information, which is approximately 0.693 nats or 0.301 decimal digits.
The rule of additivity has the following consequences: for positive integers bi where b1 + ... + bk = n, Choosing k = n, b1 = ... = bn = 1 this implies that the entropy of a certain outcome is zero: Η1(1) = 0.
This implies that the efficiency of a source set with n symbols can be defined simply as being equal to its n-ary entropy.
The measure theoretic definition in the previous section defined the entropy as a sum over expected surprisals
For example, David Ellerman's analysis of a "logic of partitions" defines a competing measure in structures dual to that of subsets of a universal set.
Another succinct axiomatic characterization of Shannon entropy was given by Aczél, Forte and Ng,[15] via the following properties: It was shown that any function
Physicists and chemists are apt to be more interested in changes in entropy as a system spontaneously evolves away from its initial conditions, in accordance with the second law of thermodynamics, rather than an unchanging probability distribution.
), W is the number of microstates (various combinations of particles in various energy states) that can yield the given macrostate, and kB is the Boltzmann constant.
Examples of the latter include redundancy in language structure or statistical properties relating to the occurrence frequencies of letter or word pairs, triplets etc.
The minimum channel capacity can be realized in theory by using the typical set or in practice using Huffman, Lempel–Ziv or arithmetic coding.
In practice, compression algorithms deliberately include some judicious redundancy in the form of checksums to protect against errors.
The entropy rate of a data source is the average number of bits per symbol needed to encode it.
[22]: 60–65 The authors estimate humankind technological capacity to store information (fully entropically compressed) in 1986 and again in 2007.
[23] A diversity index is a quantitative statistical measure of how many different types exist in a dataset, such as species in a community, accounting for ecological richness, evenness, and dominance.
There are a number of entropy-related concepts that mathematically quantify information content of a sequence or message: (The "rate of self-information" can also be defined for a particular sequence of messages or symbols generated by a given stochastic process: this will always be equal to the entropy rate in the case of a stationary process.)
In cryptanalysis, entropy is often roughly used as a measure of the unpredictability of a cryptographic key, though its real uncertainty is unmeasurable.
The corresponding formula for a continuous random variable with probability density function f(x) with finite or infinite support
To answer this question, a connection must be established between the two functions: In order to obtain a generally finite measure as the bin size goes to zero.
For example, a sequence of +1's (which are values of XH could take) have trivially low entropy and their sum would become big.
We sketch how Loomis–Whitney follows from this: Indeed, let X be a uniformly distributed random variable with values in A and so that each point in A occurs with equal probability.
Bayesian inference models often apply the principle of maximum entropy to obtain prior probability distributions.
[35] The idea is that the distribution that best represents the current state of knowledge of a system is the one with the largest entropy, and is therefore suitable to be the prior.
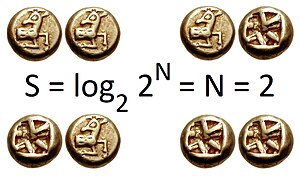

Here, the entropy is at most 1 bit, and to communicate the outcome of a coin flip (2 possible values) will require an average of at most 1 bit (exactly 1 bit for a fair coin). The result of a fair die (6 possible values) would have entropy log 2 6 bits.