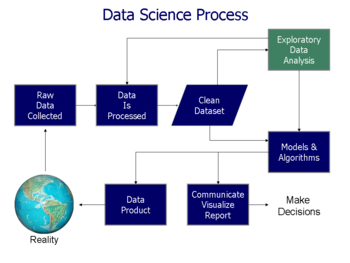
Exploratory data analysis
EDA is different from initial data analysis (IDA),[1][2] which focuses more narrowly on checking assumptions required for model fitting and hypothesis testing, and handling missing values and making transformations of variables as needed.
[4] The S programming language inspired the systems S-PLUS and R. This family of statistical-computing environments featured vastly improved dynamic visualization capabilities, which allowed statisticians to identify outliers, trends and patterns in data that merited further study.
The packages S, S-PLUS, and R included routines using resampling statistics, such as Quenouille and Tukey's jackknife and Efron's bootstrap, which are nonparametric and robust (for many problems).
[9] Typical graphical techniques used in EDA are: Dimensionality reduction: Typical quantitative techniques are: Many EDA ideas can be traced back to earlier authors, for example: The Open University course Statistics in Society (MDST 242), took the above ideas and merged them with Gottfried Noether's work, which introduced statistical inference via coin-tossing and the median test.
To illustrate, consider an example from Cook et al. where the analysis task is to find the variables which best predict the tip that a dining party will give to the waiter.
The fitted model is which says that as the size of the dining party increases by one person (leading to a higher bill), the tip rate will decrease by 1%, on average.