Full-text search
Full-text-searching techniques appeared in the 1960s, for example IBM STAIRS from 1969, and became common in online bibliographic databases in the 1990s.
[verification needed] Many websites and application programs (such as word processing software) provide full-text-search capabilities.
In the search stage, when performing a specific query, only the index is referenced, rather than the text of the original documents.
Controlled-vocabulary searching also helps alleviate low-precision issues by tagging documents in such a way that ambiguities are eliminated.
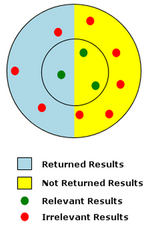
In the sample diagram to the right, false positives are represented by the irrelevant results (red dots) that were returned by the search (on a light-blue background).
Clustering techniques based on Bayesian algorithms can help reduce false positives.
The following is a partial list of available software products whose predominant purpose is to perform full-text indexing and searching.
Some of these are accompanied with detailed descriptions of their theory of operation or internal algorithms, which can provide additional insight into how full-text search may be accomplished.