Functional data analysis
The physical continuum over which these functions are defined is often time, but may also be spatial location, wavelength, probability, etc.
Functional data analysis has roots going back to work by Grenander and Karhunen in the 1940s and 1950s.
[5][6] More recently in the 1990s and 2000s the field has focused more on applications and understanding the effects of dense and sparse observations schemes.
Truncating this infinite series to a finite order underpins functional principal component analysis.
[9] Functional principal component analysis (FPCA) is the most prevalent tool in FDA, partly because FPCA facilitates dimension reduction of the inherently infinite-dimensional functional data to finite-dimensional random vector of scores.
More specifically, dimension reduction is achieved by expanding the underlying observed random trajectories
are real-valued nonnegative eigenvalues in descending order with the corresponding orthonormal eigenfunctions
The Karhunen–Loève expansion facilitates dimension reduction in the sense that the partial sum converges uniformly, i.e.,
Important applications of FPCA include the modes of variation and functional principal component regression.
Functional linear models can be divided into two types based on the responses.
Developments towards fully nonparametric regression models for functional data encounter problems such as curse of dimensionality.
In order to bypass the "curse" and the metric selection problem, we are motivated to consider nonlinear functional regression models, which are subject to some structural constraints but do not overly infringe flexibility.
By analogy to FLMs with scalar responses, estimation of functional polynomial models can be obtained through expanding both the centered covariate
[25][26] A functional multiple index model is given as below, with symbols having their usual meanings as formerly described,
Here g represents an (unknown) general smooth function defined on a p-dimensional domain.
and relatively small sample sizes, the estimator given by this model often has large variance.
ensures identifiability in the sense that the estimates of these additive component functions do not interfere with that of the intercept term
An obvious and direct extension of FLMs with scalar responses (see (3)) is to add a link function leading to a generalized functional linear model (GFLM)[30] in analogy to the generalized linear model (GLM).
The three components of the GFLM are: For vector-valued multivariate data, k-means partitioning methods and hierarchical clustering are two main approaches.
[48] A study of the asymptotic behavior of the proposed classifiers in the large sample limit shows that under certain conditions the misclassification rate converges to zero, a phenomenon that has been referred to as "perfect classification".
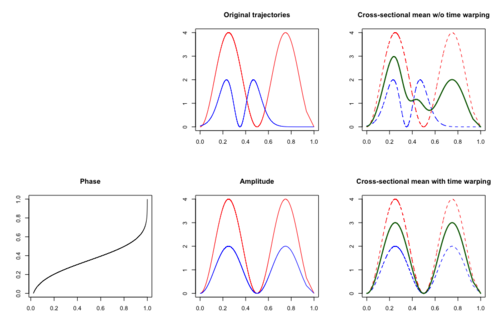
In the presence of time variation, the cross-sectional mean function may not be an efficient estimate as peaks and troughs are located randomly and thus meaningful signals may be distorted or hidden.
If both time and amplitude variation are present, then the observed functional data
The simplest case of a family of warping functions to specify phase variation is linear transformation, that is
, which warps the time of an underlying template function by subjected-specific shift and scale.
Earlier approaches include dynamic time warping (DTW) used for applications such as speech recognition.
[58] The template function is determined through an iteration process, starting from cross-sectional mean, performing registration and recalculating the cross-sectional mean for the warped curves, expecting convergence after a few iterations.
Problems of non-smooth differentiable warps or greedy computation in DTW can be resolved by adding a regularization term to the cost function.
A problem of landmark registration is that the features may be missing or hard to identify due to the noise in the data.
[59] There are Python packages to work with functional data, and its representation, perform exploratory analysis, or preprocessing, and among other tasks such as inference, classification, regression or clustering of functional data.
Some packages can handle functional data under both dense and longitudinal designs.