Huffman coding
[1] The output from Huffman's algorithm can be viewed as a variable-length code table for encoding a source symbol (such as a character in a file).
The algorithm derives this table from the estimated probability or frequency of occurrence (weight) for each possible value of the source symbol.
[2] However, although optimal among methods encoding symbols separately, Huffman coding is not always optimal among all compression methods – it is replaced with arithmetic coding[3] or asymmetric numeral systems[4] if a better compression ratio is required.
In 1951, David A. Huffman and his MIT information theory classmates were given the choice of a term paper or a final exam.
The professor, Robert M. Fano, assigned a term paper on the problem of finding the most efficient binary code.
[5] In doing so, Huffman outdid Fano, who had worked with Claude Shannon to develop a similar code.
Building the tree from the bottom up guaranteed optimality, unlike the top-down approach of Shannon–Fano coding.
We will not verify that it minimizes L over all codes, but we will compute L and compare it to the Shannon entropy H of the given set of weights; the result is nearly optimal.
As a consequence of Shannon's source coding theorem, the entropy is a measure of the smallest codeword length that is theoretically possible for the given alphabet with associated weights.
A Huffman tree that omits unused symbols produces the most optimal code lengths.
If the symbols are sorted by probability, there is a linear-time (O(n)) method to create a Huffman tree using two queues, the first one containing the initial weights (along with pointers to the associated leaves), and combined weights (along with pointers to the trees) being put in the back of the second queue.
In many cases, time complexity is not very important in the choice of algorithm here, since n here is the number of symbols in the alphabet, which is typically a very small number (compared to the length of the message to be encoded); whereas complexity analysis concerns the behavior when n grows to be very large.
For example, a communication buffer receiving Huffman-encoded data may need to be larger to deal with especially long symbols if the tree is especially unbalanced.
The process continues recursively until the last leaf node is reached; at that point, the Huffman tree will thus be faithfully reconstructed.
In any case, since the compressed data can include unused "trailing bits" the decompressor must be able to determine when to stop producing output.
This can be accomplished by either transmitting the length of the decompressed data along with the compression model or by defining a special code symbol to signify the end of input (the latter method can adversely affect code length optimality, however).
The probabilities used can be generic ones for the application domain that are based on average experience, or they can be the actual frequencies found in the text being compressed.
Huffman's original algorithm is optimal for a symbol-by-symbol coding with a known input probability distribution, i.e., separately encoding unrelated symbols in such a data stream.
Also, if symbols are not independent and identically distributed, a single code may be insufficient for optimality.
As of mid-2010, the most commonly used techniques for this alternative to Huffman coding have passed into the public domain as the early patents have expired.
Huffman coding is optimal among all methods in any case where each input symbol is a known independent and identically distributed random variable having a probability that is dyadic.
The worst case for Huffman coding can happen when the probability of the most likely symbol far exceeds 2−1 = 0.5, making the upper limit of inefficiency unbounded.
This technique adds one step in advance of entropy coding, specifically counting (runs) of repeated symbols, which are then encoded.
Note that for n greater than 2, not all sets of source words can properly form an n-ary tree for Huffman coding.
A variation called adaptive Huffman coding involves calculating the probabilities dynamically based on recent actual frequencies in the sequence of source symbols, and changing the coding tree structure to match the updated probability estimates.
It is used rarely in practice, since the cost of updating the tree makes it slower than optimized adaptive arithmetic coding, which is more flexible and has better compression.
An example is the encoding alphabet of Morse code, where a 'dash' takes longer to send than a 'dot', and therefore the cost of a dash in transmission time is higher.
[11] In the standard Huffman coding problem, it is assumed that any codeword can correspond to any input symbol.
A later method, the Garsia–Wachs algorithm of Adriano Garsia and Michelle L. Wachs (1977), uses simpler logic to perform the same comparisons in the same total time bound.
[citation needed] Prefix codes nevertheless remain in wide use because of their simplicity, high speed, and lack of patent coverage.
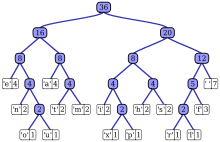
| Char | Freq | Code |
|---|---|---|
| space | 7 | 111 |
| a | 4 | 010 |
| e | 4 | 000 |
| f | 3 | 1101 |
| h | 2 | 1010 |
| i | 2 | 1000 |
| m | 2 | 0111 |
| n | 2 | 0010 |
| s | 2 | 1011 |
| t | 2 | 0110 |
| l | 1 | 11001 |
| o | 1 | 00110 |
| p | 1 | 10011 |
| r | 1 | 11000 |
| u | 1 | 00111 |
| x | 1 | 10010 |





| Symbol | Code |
|---|---|
| a1 | 0 |
| a2 | 10 |
| a3 | 110 |
| a4 | 111 |