ISO/IEC 9995
[1] The project of this standard was adopted at ISO in Berlin in 1985 under the proposition of Dr Yves Neuville.
ISO/IEC 9995-1 provides a fundamental description of keyboards suitable for text and office systems, and defines several terms which are used throughout the ISO/IEC 9995 standard series.
The characters which can be input by the keys in the alphanumeric section usually are organized in levels.
Usually (but not mandatory by the standard), characters in such a level are selected by the means of an AltGr key.
This implies that Japanese keyboards containing muhenkan, henkan, and the Katakana/Hiragana switch keys (the first one left, the other two right of the space bar) are not compliant to the standard if taken literally.
The reference grid position of any function key may vary according to the specifications listed below.
The left one shall occupy position B99, while the right one shall be located right of the character input keys of that row.
An informative annex “Allocation guidelines” provides a basic pattern for arrangements of Latin letters, which in fact specifies a foundation for the kinds of keyboard layouts known as QWERTY, QWERTZ, or AZERTY.
As this annex is not normative, it does not prevent other arrangements like the Dvorak keyboard or the Turkish F-keyboard being compliant to the ISO/IEC 9995 standard series.
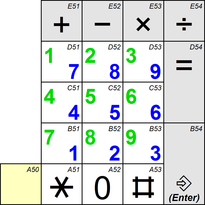
The amendment 1 of ISO/IEC 9995-2:2009, which was published in 2012, specifies two ways of the emulation of a numeric keypad within the alphanumeric section of a keyboard.
One way, with mappings to keys in the left half of the alphanumeric section (shown green in the diagram above), emulates a numeric keypad with the digits 1,2,3 in the upper row.
The other way, with mappings to keys in the right half (shown blue in the diagram above), emulates one with the digits 7,8,9 in the upper row.
These are engraved on the right part of the keytops; the standard defines their position independent of the characters of the primary layout.
The diacritical marks contained in the common secondary group act as dead keys, i.e. they are to be entered before the base characters they apply to.
This mechanism is also to be used for sequences of more than one diacritical marks, to write languages like Vietnamese and Navajo.
Moreover, ISO/IEC 9995-3:2010 defines a list of “Peculiar Characters which can be entered as combinations using diacritical marks”.
The third edition ISO/IEC 9995-3:2010 additionally defines an “outdated common secondary group” for compatibility purposes only.
It is based on the “harmonized 48 graphic key keyboard arrangement” as defined in ISO/IEC 9995-2 (see description above).
The leftmost key in the lowest row may span to the left, occupying the position shown with yellow background.
On a keyboard used for office purposes, the key denoted by ⌗ shall show the decimal separator (usually a dot or a comma, dependent on the user language).
Some of these symbols have been encoded as Unicode code points; the figure shown above in the ISO/IEC 9995-2 section shows several examples.
The rest have been proposed for encoding,[22] but (as of November 2021) have been postponed pending evidence of use in running text other than by ISO and DIN.
[25] ISO/IEC 9995-8:2009 defines an assignment identical to E.161 of the 26 letters A–Z to the number keys of a numeric keypad.
[26] ISO/IEC 9995-10 specifies several symbols to enable the unique identification of characters on keytops which otherwise can easily be misidentified (as em vs. en dashes).
There is a publicly available listing of these symbols in a proposal to encode them as Unicode characters[22] (which has been postponed for lack of demonstrated use, as of November 2021).