Kolmogorov complexity
In algorithmic information theory (a subfield of computer science and mathematics), the Kolmogorov complexity of an object, such as a piece of text, is the length of a shortest computer program (in a predetermined programming language) that produces the object as output.
It is named after Andrey Kolmogorov, who first published on the subject in 1963[1][2] and is a generalization of classical information theory.
The notion of Kolmogorov complexity can be used to state and prove impossibility results akin to Cantor's diagonal argument, Gödel's incompleteness theorem, and Turing's halting problem.
In particular, no program P computing a lower bound for each text's Kolmogorov complexity can return a value essentially larger than P's own length (see section § Chaitin's incompleteness theorem); hence no single program can compute the exact Kolmogorov complexity for infinitely many texts.
Kolmogorov complexity is the length of the ultimately compressed version of a file (i.e., anything which can be put in a computer).
The Kolmogorov complexity can be defined for any mathematical object, but for simplicity the scope of this article is restricted to strings.
For theoretical analysis, this approach is more suited for constructing detailed formal proofs and is generally preferred in the research literature.
This gives us the following formal way to describe K.[6] Note that some universal Turing machines may not be programmable with prefix codes.
The concept and theory of Kolmogorov Complexity is based on a crucial theorem first discovered by Ray Solomonoff, who published it in 1960, describing it in "A Preliminary Report on a General Theory of Inductive Inference"[7] as part of his invention of algorithmic probability.
[11] The theorem says that, among algorithms that decode strings from their descriptions (codes), there exists an optimal one.
Kolmogorov used this theorem to define several functions of strings, including complexity, randomness, and information.
The general consensus in the scientific community, however, was to associate this type of complexity with Kolmogorov, who was concerned with randomness of a sequence, while Algorithmic Probability became associated with Solomonoff, who focused on prediction using his invention of the universal prior probability distribution.
The computer scientist Ming Li considers this an example of the Matthew effect: "...to everyone who has, more will be given..."[13] There are several other variants of Kolmogorov complexity or algorithmic information.
The most widely used one is based on self-delimiting programs, and is mainly due to Leonid Levin (1974).
For the plain complexity, just write a program that simply copies the input to the output.
In other words, there is no program which takes any string s as input and produces the integer K(s) as output.
All programs are of finite length so, for sake of proof simplicity, assume it to be 7000000000 bits.
[19] There is a corollary, humorously called the "full employment theorem" in the programming language community, stating that there is no perfect size-optimizing compiler.
[note 6] For the same reason, most strings are complex in the sense that they cannot be significantly compressed – their K(s) is not much smaller than |s|, the length of s in bits.
To make this precise, fix a value of n. There are 2n bitstrings of length n. The uniform probability distribution on the space of these bitstrings assigns exactly equal weight 2−n to each string of length n. Theorem: With the uniform probability distribution on the space of bitstrings of length n, the probability that a string is incompressible by c is at least 1 − 2−c+1 + 2−n.
Theorem: There exists a constant L (which only depends on S and on the choice of description language) such that there does not exist a string s for which the statement can be proven within S.[21][22] Proof Idea: The proof of this result is modeled on a self-referential construction used in Berry's paradox.
So it is not possible for the proof system S to prove K(x) ≥ L for L arbitrarily large, in particular, for L larger than the length of the procedure P, (which is finite).
Finally, consider the program consisting of all these procedure definitions, and a main call: where the constant n0 will be determined later on.
The minimum message length principle of statistical and inductive inference and machine learning was developed by C.S.
It has the desirable properties of statistical invariance (i.e. the inference transforms with a re-parametrisation, such as from polar coordinates to Cartesian coordinates), statistical consistency (i.e. even for very hard problems, MML will converge to any underlying model) and efficiency (i.e. the MML model will converge to any true underlying model about as quickly as is possible).
Dowe (1999) showed a formal connection between MML and algorithmic information theory (or Kolmogorov complexity).
This definition can be extended to define a notion of randomness for infinite sequences from a finite alphabet.
[25] For dynamical systems, entropy rate and algorithmic complexity of the trajectories are related by a theorem of Brudno, that the equality
, but that the universal Turing machine would halt at some point after reading the initial segment
is, roughly speaking, defined as the Kolmogorov complexity of x given y as an auxiliary input to the procedure.

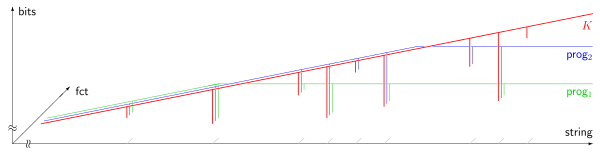
prog1(s)
,
prog2(s)
. The horizontal axis (
logarithmic scale
) enumerates all
strings
s
, ordered by length; the vertical axis (
linear scale
) measures Kolmogorov complexity in
bits
. Most strings are incompressible, i.e. their Kolmogorov complexity exceeds their length by a constant amount. 9 compressible strings are shown in the picture, appearing as almost vertical slopes. Due to Chaitin's incompleteness theorem (1974), the output of any program computing a lower bound of the Kolmogorov complexity cannot exceed some fixed limit, which is independent of the input string
s
.