LR parser
But by convention, the LR name stands for the form of parsing invented by Donald Knuth, and excludes the earlier, less powerful precedence methods (for example Operator-precedence parser).
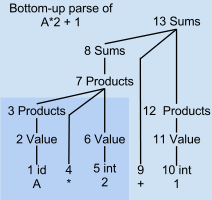
Step 6 applies a grammar rule with multiple parts: This matches the stack top holding the parsed phrases "... Products * Value".
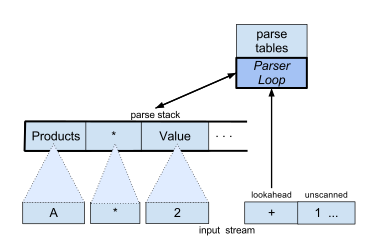
The parser's next action is determined by its current LR(0) state number (rightmost on the stack) and the lookahead symbol.
When state 3 sees the lookahead eof, it knows to apply the completed grammar rule by combining the stack's rightmost three phrases for Sums, +, and Products into one thing.
LR parsers are constructed from a grammar that formally defines the syntax of the input language as a set of patterns.
The grammar doesn't cover all language rules, such as the size of numbers, or the consistent use of names and their definitions in the context of the whole program.
Here these include + * and int for any integer constant, and id for any identifier name, and eof for end of input file.
Grammars for complete languages use recursive rules to handle lists, parenthesized expressions, and nested statements.
Entries in a table show whether to shift or reduce (and by which grammar rule), for every legal combination of parser state and lookahead symbol.
These cells show which state to advance to, after some reduction's Left Hand Side has created an expected new instance of that symbol.
The table column "Current Rules" documents the meaning and syntax possibilities for each state, as worked out by the parser generator.
When a Products has been found, the parser advances to state 3 to accumulate the complete list of summands and find the end of rule r0.
Individual table cells must not hold multiple, alternative actions, otherwise the parser would be nondeterministic with guesswork and backtracking.
The LR parser begins with a nearly empty parse stack containing just the start state 0, and with the lookahead holding the input stream's first scanned symbol.
So int leads to next state 8 with core If the same follower symbol appears in several items, the parser cannot yet tell which rule applies here.
Another way to view this, is that the finite state machine can scan the stream "Products * int + 1" (without using yet another stack) and find the leftmost complete phrase that should be reduced next.
How can a mere FSM do this when the original unparsed language has nesting and recursion and definitely requires an analyzer with a stack?
In SLR parsers, these lookahead sets are determined directly from the grammar, without considering the individual states and transitions.
Each occurrence of a symbol S in the grammar can be treated independently with its own lookahead set, to help resolve reduction conflicts.
This splitting of states can also be done manually and selectively with any SLR or LALR parser, by making two or more named copies of some nonterminals.
SLR, LALR, and canonical LR parsers make exactly the same shift and reduce decisions when the input stream is the correct language.
This happens because the SLR and LALR parsers are using a generous superset approximation to the true, minimal lookahead symbols for that particular state.
Repair of syntax errors is easiest to do consistently in parsers (like LR) that have parse tables and an explicit data stack.
These decisions are usually turned into read-only data tables that drive a generic parser loop that is grammar- and state-independent.
Some LR parser generators create separate tailored program code for each state, rather than a parse table.
[citation needed] In other words, if a language was reasonable enough to allow an efficient one-pass parser, it could be described by an LR(k) grammar.
[citation needed] The canonical LR parsers described by Knuth had too many states and very big parse tables that were impractically large for the limited memory of computers of that era.
LR parsing became practical when Frank DeRemer invented SLR and LALR parsers with much fewer states.
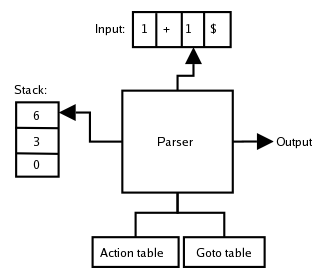
[14] This example of LR parsing uses the following small grammar with goal symbol E: to parse the following input: The two LR(0) parsing tables for this grammar look as follows: The action table is indexed by a state of the parser and a terminal (including a special terminal $ that indicates the end of the input stream) and contains three types of actions: The goto table is indexed by a state of the parser and a nonterminal and simply indicates what the next state of the parser will be if it has recognized a certain nonterminal.
For the sake of explaining the symbol (e.g., '1', B) is shown that caused the transition to the next state, although strictly speaking it is not part of the stack.