Synchronization (computer science)
In computer science, synchronization is the task of coordinating multiple processes to join up or handshake at a certain point, in order to reach an agreement or commit to a certain sequence of action.
If proper synchronization techniques[1] are not applied, it may cause a race condition where the values of variables may be unpredictable and vary depending on the timings of context switches of the processes or threads.
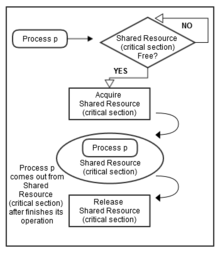
All three of them are concurrently executing, and they need to share a common resource (critical section) as shown in Figure 1.
Similarly, one cannot check e-mails before validating the appropriate credentials (for example, user name and password).
Experiments have shown that (global) communications due to synchronization on distributed computers takes a dominated share in a sparse iterative solver.
[2] This problem is receiving increasing attention after the emergence of a new benchmark metric, the High Performance Conjugate Gradient(HPCG),[3] for ranking the top 500 supercomputers.
Synchronization overheads can significantly impact performance in parallel computing environments, where merging data from multiple processes can incur costs substantially higher—often by two or more orders of magnitude—than processing the same data on a single thread, primarily due to the additional overhead of inter-process communication and synchronization mechanisms.
In general, architects do not expect users to employ the basic hardware primitives, but instead expect that the primitives will be used by system programmers to build a synchronization library, a process that is often complex and tricky.
"[8] Many modern pieces of hardware provide such atomic instructions, two common examples being: test-and-set, which operates on a single memory word, and compare-and-swap, which swaps the contents of two memory words.
In Java, one way to prevent thread interference and memory consistency errors, is by prefixing a method signature with the synchronized keyword, in which case the lock of the declaring object is used to enforce synchronization.
A second way is to wrap a block of code in a synchronized(someObject){...} section, which offers finer-grain control.
This forces any thread to acquire the lock of someObject before it can execute the contained block.
Before accessing any shared resource or piece of code, every processor checks a flag.
[14] Experiments show that 34% of the total execution time is spent in waiting for other slower threads.
Although locks were derived for file databases, data is also shared in memory between processes and threads.
Java and Ada only have exclusive locks because they are thread based and rely on the compare-and-swap processor instruction.
There are also many higher-level theoretical devices, such as process calculi and Petri nets, which can be built on top of the history monoid.
Prior to kernel version 2.6, Linux disabled interrupt to implement short critical sections.