Receiver operating characteristic
ROC analysis provides tools to select possibly optimal models and to discard suboptimal ones independently from (and prior to specifying) the cost context or the class distribution.
ROC analysis has been used in medicine, radiology, biometrics, forecasting of natural hazards,[4] meteorology,[5] model performance assessment,[6] and other areas for many decades and is increasingly used in machine learning and data mining research.
Because the classifier or diagnosis result can be an arbitrary real value (continuous output), the classifier boundary between classes must be determined by a threshold value (for instance, to determine whether a person has hypertension based on a blood pressure measure).
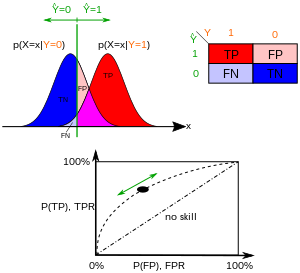
Conversely, a true negative (TN) has occurred when both the prediction outcome and the actual value are n, and a false negative (FN) is when the prediction outcome is n while the actual value is p. To get an appropriate example in a real-world problem, consider a diagnostic test that seeks to determine whether a person has a certain disease.
FPR, on the other hand, defines how many incorrect positive results occur among all negative samples available during the test.
As the size of the sample increases, a random classifier's ROC point tends towards the diagonal line.
In binary classification, the class prediction for each instance is often made based on a continuous random variable
A medical test might measure the level of a certain protein in a blood sample and classify any number above a certain threshold as indicating disease.
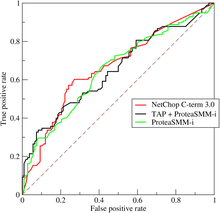
The experimenter can adjust the threshold (green vertical line in the figure), which will in turn change the false positive rate.
Moreover, that portion of AUC indicates a space with high or low confusion matrix threshold which is rarely of interest for scientists performing a binary classification in any field.
[19] Another criticism to the ROC and its area under the curve is that they say nothing about precision and negative predictive value.
The ROC AUC summarizes sensitivity and specificity, but does not inform regarding precision and negative predictive value.
Common versions are: However, any attempt to summarize the ROC curve into a single number loses information about the pattern of tradeoffs of the particular discriminator algorithm.
The area under the curve (often referred to as simply the AUC) is equal to the probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative one (assuming 'positive' ranks higher than 'negative').
is a special case of Somers' D. It is also common to calculate the Area Under the ROC Convex Hull (ROC AUCH = ROCH AUC) as any point on the line segment between two prediction results can be achieved by randomly using one or the other system with probabilities proportional to the relative length of the opposite component of the segment.
[38] Another problem with ROC AUC is that reducing the ROC Curve to a single number ignores the fact that it is about the tradeoffs between the different systems or performance points plotted and not the performance of an individual system, as well as ignoring the possibility of concavity repair, so that related alternative measures such as Informedness[citation needed] or DeltaP are recommended.
[citation needed] Whereas ROC AUC varies between 0 and 1 — with an uninformative classifier yielding 0.5 — the alternative measures known as Informedness,[citation needed] Certainty [23] and Gini Coefficient (in the single parameterization or single system case)[citation needed] all have the advantage that 0 represents chance performance whilst 1 represents perfect performance, and −1 represents the "perverse" case of full informedness always giving the wrong response.
[42] For example, one could focus on the region of the curve with low false positive rate, which is often of prime interest for population screening tests.
[45] The Total Operating Characteristic (TOC) also characterizes diagnostic ability while revealing more information than the ROC.
The analysis of the ROC performance in graphs with this warping of the axes was used by psychologists in perception studies halfway through the 20th century,[citation needed] where this was dubbed "double probability paper".
The linearity of the zROC curve depends on the standard deviations of the target and lure strength distributions.
Although d' is a commonly used parameter, it must be recognized that it is only relevant when strictly adhering to the very strong assumptions of strength theory made above.
This difference in shape and slope result from an added element of variability due to some items being recollected.
Patients with anterograde amnesia are unable to recollect, so their Yonelinas zROC curve would have a slope close to 1.0.
[55] Following the attack on Pearl Harbor in 1941, the United States military began new research to increase the prediction of correctly detected Japanese aircraft from their radar signals.
[56] In the 1950s, ROC curves were employed in psychophysics to assess human (and occasionally non-human animal) detection of weak signals.
[57][58] ROC curves are also used extensively in epidemiology and medical research and are frequently mentioned in conjunction with evidence-based medicine.
From this figure, the common entries in the radar range equation (with noise factors) may be solved, to estimate the required effective radiated power.
Two common approaches for when there are multiple classes are (1) average over all pairwise AUC values[63] and (2) compute the volume under surface (VUS).
Every possible decision rule that one might use for a classifier for c classes can be described in terms of its true positive rates (TPR1, . . . , TPRc).