Read-copy-update
In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures (e.g., linked lists, trees, hash tables).
[1] It is used when performance of reads is crucial and is an example of space–time tradeoff, enabling fast operations at the cost of more space.
This overview starts by showing how data can be safely inserted into and deleted from linked structures despite concurrent readers.
The first state shows a global pointer named gptr that is initially NULL, colored red to indicate that it might be accessed by a reader at any time, thus requiring updaters to take care.
This structure has indeterminate state (indicated by the question marks) but is inaccessible to readers (indicated by the green color).
This is in stark contrast with more traditional synchronization primitives such as locking or transactions that coordinate in time, but not in space.
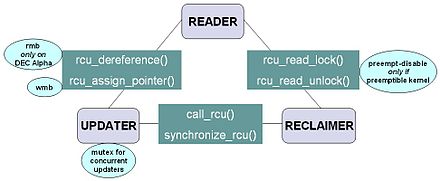
Any statement that is not within an RCU read-side critical section is said to be in a quiescent state, and such statements are not permitted to hold references to RCU-protected data structures, nor is the wait-for-readers operation required to wait for threads in quiescent states.
[7] By early 2008, there were almost 2,000 uses of the RCU API within the Linux kernel[8] including the networking protocol stacks[9] and the memory-management system.
In contrast, in more conventional lock-based schemes, readers must use heavy-weight synchronization in order to prevent an updater from deleting the data structure out from under them.
In contrast, RCU-based updaters typically take advantage of the fact that writes to single aligned pointers are atomic on modern CPUs, allowing atomic insertion, removal, and replacement of data in a linked structure without disrupting readers.
Concurrent RCU readers can then continue accessing the old versions and can dispense with the atomic read-modify-write instructions, memory barriers, and cache misses that are so expensive on modern SMP computer systems, even in absence of lock contention.
[18][19] The lightweight nature of RCU's read-side primitives provides additional advantages beyond excellent performance, scalability, and real-time response.
For example, RCU is a specialized technique that works best in situations with mostly reads and few updates but is often less applicable to update-only workloads.
Efficient implementations of the RCU infrastructure make heavy use of batching in order to amortize their overhead over many uses of the corresponding APIs.
However, they are needed in order to suppress harmful compiler optimization and to prevent CPUs from reordering accesses.
This is the great strength of classic RCU in a non-preemptive kernel: read-side overhead is precisely zero, as smp_read_barrier_depends() is an empty macro on all but DEC Alpha CPUs;[23][failed verification] such memory barriers are not needed on modern CPUs.
And there is no way that rcu_read_lock can participate in a deadlock cycle, cause a realtime process to miss its scheduling deadline, precipitate priority inversion, or result in high lock contention.
The implementation of synchronize_rcu moves the caller of synchronize_cpu to each CPU, thus blocking until all CPUs have been able to perform the context switch.
Once all CPUs have executed a context switch, then all preceding RCU read-side critical sections will have completed.
Techniques and mechanisms resembling RCU have been independently invented multiple times:[25] Bauer, R.T., (June 2009), "Operational Verification of a Relativistic Program" PSU Tech Report TR-09-04 (http://www.pdx.edu/sites/www.pdx.edu.computer-science/files/tr0904.pdf)