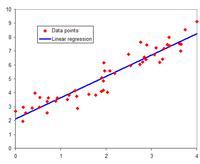
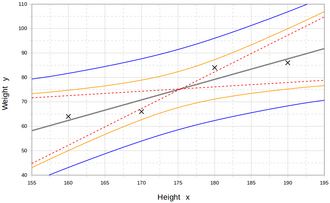
Regression analysis
First, regression analysis is widely used for prediction and forecasting, where its use has substantial overlap with the field of machine learning.
Second, in some situations regression analysis can be used to infer causal relationships between the independent and dependent variables.
The latter is especially important when researchers hope to estimate causal relationships using observational data.
[2][3] The earliest regression form was seen in Isaac Newton's work in 1700 while studying equinoxes, being credited with introducing "an embryonic linear aggression analysis" as "Not only did he perform the averaging of a set of data, 50 years before Tobias Mayer, but summing the residuals to zero he forced the regression line to pass through the average point.
[7] Legendre and Gauss both applied the method to the problem of determining, from astronomical observations, the orbits of bodies about the Sun (mostly comets, but also later the then newly discovered minor planets).
The term "regression" was coined by Francis Galton in the 19th century to describe a biological phenomenon.
[9][10] For Galton, regression had only this biological meaning,[11][12] but his work was later extended by Udny Yule and Karl Pearson to a more general statistical context.
[13][14] In the work of Yule and Pearson, the joint distribution of the response and explanatory variables is assumed to be Gaussian.
Modern regression analysis is typically done with statistical and spreadsheet software packages on computers as well as on handheld scientific and graphing calculators.
Regression models involve the following components: In various fields of application, different terminologies are used in place of dependent and independent variables.
This important assumption is often overlooked, although errors-in-variables models can be used when the independent variables are assumed to contain errors.
Once researchers determine their preferred statistical model, different forms of regression analysis provide tools to estimate the parameters
to distinguish the estimate from the true (unknown) parameter value that generated the data.
[7] However, alternative variants (e.g., least absolute deviations or quantile regression) are useful when researchers want to model other functions
In order to interpret the output of regression as a meaningful statistical quantity that measures real-world relationships, researchers often rely on a number of classical assumptions.
Practitioners have developed a variety of methods to maintain some or all of these desirable properties in real-world settings, because these classical assumptions are unlikely to hold exactly.
For example, modeling errors-in-variables can lead to reasonable estimates independent variables are measured with errors.
The denominator is the sample size reduced by the number of model parameters estimated from the same data,
Commonly used checks of goodness of fit include the R-squared, analyses of the pattern of residuals and hypothesis testing.
Statistical significance can be checked by an F-test of the overall fit, followed by t-tests of individual parameters.
With relatively large samples, however, a central limit theorem can be invoked such that hypothesis testing may proceed using asymptotic approximations.
The response variable may be non-continuous ("limited" to lie on some subset of the real line).
When the model function is not linear in the parameters, the sum of squares must be minimized by an iterative procedure.
Such intervals tend to expand rapidly as the values of the independent variable(s) moved outside the range covered by the observed data.
A properly conducted regression analysis will include an assessment of how well the assumed form is matched by the observed data, but it can only do so within the range of values of the independent variables actually available.
This means that any extrapolation is particularly reliant on the assumptions being made about the structural form of the regression relationship.
The implications of this step of choosing an appropriate functional form for the regression can be great when extrapolation is considered.
is the number of observations needed to reach the desired precision if the model had only one independent variable.
) the model can support is 4, because Although the parameters of a regression model are usually estimated using the method of least squares, other methods which have been used include: All major statistical software packages perform least squares regression analysis and inference.
While many statistical software packages can perform various types of nonparametric and robust regression, these methods are less standardized.