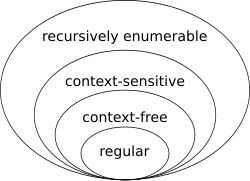
Regular language
Other typical examples include the language consisting of all strings over the alphabet {a, b} which contain an even number of a's, or the language consisting of all strings of the form: several a's followed by several b's.
A simple example of a language that is not regular is the set of strings {anbn | n ≥ 0}.
A regular language satisfies the following equivalent properties: Properties 10. and 11. are purely algebraic approaches to define regular languages; a similar set of statements can be formulated for a monoid M ⊆ Σ*.
In this case, equivalence over M leads to the concept of a recognizable language.
Some of the equivalences above, particularly those among the first four formalisms, are called Kleene's theorem in textbooks.
One textbook calls the equivalence of regular expressions and NFAs ("1."
[6] Another textbook calls the equivalence of regular expressions and DFAs ("1."
[7] Two other textbooks first prove the expressive equivalence of NFAs and DFAs ("2."
and then state "Kleene's theorem" as the equivalence between regular expressions and finite automata (the latter said to describe "recognizable languages").
[2][8] A linguistically oriented text first equates regular grammars ("4."
above) with DFAs and NFAs, calls the languages generated by (any of) these "regular", after which it introduces regular expressions which it terms to describe "rational languages", and finally states "Kleene's theorem" as the coincidence of regular and rational languages.
[9] Other authors simply define "rational expression" and "regular expressions" as synonymous and do the same with "rational languages" and "regular languages".
[1][2] Apparently, the term "regular" originates from a 1951 technical report where Kleene introduced "regular events" and explicitly welcomed "any suggestions as to a more descriptive term".
[10] Noam Chomsky, in his 1959 seminal article, used the term "regular" in a different meaning at first (referring to what is called "Chomsky normal form" today),[11] but noticed that his "finite state languages" were equivalent to Kleene's "regular events".
[17] As a consequence, using the above closure properties, the following problems are also decidable for arbitrarily given deterministic finite automata A and B, with accepted languages LA and LB, respectively: For regular expressions, the universality problem is NP-complete already for a singleton alphabet.
[19] If regular expressions are extended to allow also a squaring operator, with "A2" denoting the same as "AA", still just regular languages can be described, but the universality problem has an exponential space lower bound,[20][21][22] and is in fact complete for exponential space with respect to polynomial-time reduction.
[23] For a fixed finite alphabet, the theory of the set of all languages — together with strings, membership of a string in a language, and for each character, a function to append the character to a string (and no other operations) — is decidable, and its minimal elementary substructure consists precisely of regular languages.
[24] In computational complexity theory, the complexity class of all regular languages is sometimes referred to as REGULAR or REG and equals DSPACE(O(1)), the decision problems that can be solved in constant space (the space used is independent of the input size).
In practice, most nonregular problems are solved by machines taking at least logarithmic space.
The converse is not true: for example, the language consisting of all strings having the same number of a's as b's is context-free but not regular.
To prove that a language is not regular, one often uses the Myhill–Nerode theorem and the pumping lemma.
Other approaches include using the closure properties of regular languages[28] or quantifying Kolmogorov complexity.
Consider, for example, the Dyck language of strings of balanced parentheses.
, but the number of words of even or odd length are of this form; the corresponding eigenvalues are
In general, for every regular language there exists a constant
Rational set generalizes the notion (of regular/rational language) to monoids that are not necessarily free.
Howard Straubing notes in relation to these facts that “The term "regular language" is a bit unfortunate.
Papers influenced by Eilenberg's monograph[40] often use either the term "recognizable language", which refers to the behavior of automata, or "rational language", which refers to important analogies between regular expressions and rational power series.
(In fact, Eilenberg defines rational and recognizable subsets of arbitrary monoids; the two notions do not, in general, coincide.)
This terminology, while better motivated, never really caught on, and "regular language" is used almost universally.”[41] Rational series is another generalization, this time in the context of a formal power series over a semiring.