Resource Description Framework
The Resource Description Framework (RDF) is a method to describe and exchange graph data.
It was originally designed as a data model for metadata by the World Wide Web Consortium (W3C).
It provides a variety of syntax notations and formats, of which the most widely used is Turtle (Terse RDF Triple Language).
This simple, flexible data model has a lot of expressive power to represent complex situations, relationships, and other things of interest, while also being appropriately abstract.
As RDFS, OWL and SHACL demonstrate, one can build additional ontology languages upon RDF.
The initial RDF design, intended to "build a vendor-neutral and operating system- independent system of metadata",[2] derived from the W3C's Platform for Internet Content Selection (PICS), an early web content labelling system,[3] but the project was also shaped by ideas from Dublin Core, and from the Meta Content Framework (MCF),[2] which had been developed during 1995 to 1997 by Ramanathan V. Guha at Apple and Tim Bray at Netscape.
[4] A first public draft of RDF appeared in October 1997,[5][6] issued by a W3C working group that included representatives from IBM, Microsoft, Netscape, Nokia, Reuters, SoftQuad, and the University of Michigan.
With a little effort, virtually any arbitrary XML may also be interpreted as RDF using GRDDL (pronounced 'griddle'), Gleaning Resource Descriptions from Dialects of Languages.
[35] In Semantic Web applications, and in relatively popular applications of RDF like RSS and FOAF (Friend of a Friend), resources tend to be represented by URIs that intentionally denote, and can be used to access, actual data on the World Wide Web.
However, there is broad agreement that a bare URI (without a # symbol) which returns a 300-level coded response when used in an HTTP GET request should be treated as denoting the internet resource that it succeeds in accessing.
The intent of publishing RDF-based ontologies on the Web is often to establish, or circumscribe, the intended meanings of the resource identifiers used to express data in RDF.
is intended by its owners to refer to the class of all Merlot red wines by vintner (i.e., instances of the above URI each represent the class of all wine produced by a single vintner), a definition which is expressed by the OWL ontology — itself an RDF document — in which it occurs.
Without careful analysis of the definition, one might erroneously conclude that an instance of the above URI was something physical, instead of a type of wine.
Reification is sometimes important in order to deduce a level of confidence or degree of usefulness for each statement.
Borrowing from concepts available in logic (and as illustrated in graphical notations such as conceptual graphs and topic maps), some RDF model implementations acknowledge that it is sometimes useful to group statements according to different criteria, called situations, contexts, or scopes, as discussed in articles by RDF specification co-editor Graham Klyne.
SHACL Core consists of a list of built-in constraints such as cardinality, range of values and many others.
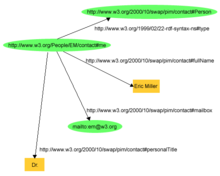
Both versions of the statements above are wordy because one requirement for an RDF resource (as a subject or a predicate) is that it be unique.
The predicate needs to be unique in order to reduce the chance that the idea of Title or Publisher will be ambiguous to software working with the description.
The following example, written in Turtle, shows how such simple claims can be elaborated on, by combining multiple RDF vocabularies.
Here, we note that the primary topic of the Wikipedia page is a "Person" whose name is "Tony Benn": Some uses of RDF include research into social networking.
It will also help people in business fields understand better their relationships with members of industries that could be of use for product placement.