Single instruction, multiple data
Single instruction, multiple data (SIMD) is a type of parallel processing in Flynn's taxonomy.
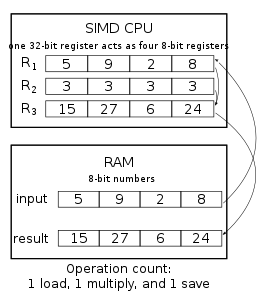
Each hardware element(PU) working on individual data item sometimes also referred as SIMD lane or channel.
Modern graphics processing units (GPUs) are often wide SIMD(typically >16 data lanes or channel) implementations.
The first era of modern SIMD computers was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2.
[citation needed] An order of magnitude increase in code size is not uncommon, when compared to equivalent scalar or equivalent vector code, and an order of magnitude or greater effectiveness (work done per instruction) is achievable with Vector ISAs.
[6] ARM's Scalable Vector Extension takes another approach, known in Flynn's Taxonomy as "Associative Processing", more commonly known today as "Predicated" (masked) SIMD.
Small-scale (64 or 128 bits) SIMD became popular on general-purpose CPUs in the early 1990s and continued through 1997 and later with Motion Video Instructions (MVI) for Alpha.
SIMD instructions can be found, to one degree or another, on most CPUs, including IBM's AltiVec and SPE for PowerPC, HP's PA-RISC Multimedia Acceleration eXtensions (MAX), Intel's MMX and iwMMXt, SSE, SSE2, SSE3 SSSE3 and SSE4.x, AMD's 3DNow!, ARC's ARC Video subsystem, SPARC's VIS and VIS2, Sun's MAJC, ARM's Neon technology, MIPS' MDMX (MaDMaX) and MIPS-3D.
The IBM, Sony, Toshiba co-developed Cell Processor's SPU's instruction set is heavily SIMD based.
Some systems also include permute functions that re-pack elements inside vectors, making them particularly useful for data processing and compression.
Adoption of SIMD systems in personal computer software was at first slow, due to a number of problems.
One was that many of the early SIMD instruction sets tended to slow overall performance of the system due to the re-use of existing floating point registers.
Intel and AMD now both provide optimized math libraries that use SIMD instructions, and open source alternatives like libSIMD, SIMDx86 and SLEEF have started to appear (see also libm).
It is common for publishers of the SIMD instruction sets to make their own C/C++ language extensions with intrinsic functions or special datatypes (with operator overloading) guaranteeing the generation of vector code.
Intel, AltiVec, and ARM NEON provide extensions widely adopted by the compilers targeting their CPUs.
The GNU C Compiler takes the extensions a step further by abstracting them into a universal interface that can be used on any platform by providing a way of defining SIMD datatypes.
Instead of providing an SIMD datatype, compilers can also be hinted to auto-vectorize some loops, potentially taking some assertions about the lack of data dependency.
[19] Consumer software is typically expected to work on a range of CPUs covering multiple generations, which could limit the programmer's ability to use new SIMD instructions to improve the computational performance of a program.
The solution is to include multiple versions of the same code that uses either older or newer SIMD technologies, and pick one that best fits the user's CPU at run-time (dynamic dispatch).
There are two main camps of solutions: FMV, manually coded in assembly language, is quite commonly used in a number of performance-critical libraries such as glibc and libjpeg-turbo.
GCC and clang requires explicit target_clones labels in the code to "clone" functions,[20] while ICC does so automatically (under the command-line option /Qax).
The setup is similar to GCC and Clang in that the code defines what instruction sets to compile for, but cloning is manually done via inlining.
[21] As using FMV requires code modification on GCC and Clang, vendors more commonly use library multi-versioning: this is easier to achieve as only compiler switches need to be changed.
Benchmarks for 4×4 matrix multiplication, 3D vertex transformation, and Mandelbrot set visualization show near 400% speedup compared to scalar code written in Dart.
3D graphics applications tend to lend themselves well to SIMD processing as they rely heavily on operations with 4-dimensional vectors.
It uses a number of SIMD processors (a NUMA architecture, each with independent local store and controlled by a general purpose CPU) and is geared towards the huge datasets required by 3D and video processing applications.