Unification (computer science)
For example, using x,y,z as variables, and taking f to be an uninterpreted function, the singleton equation set { f(1,y) = f(x,2) } is a syntactic first-order unification problem that has the substitution { x ↦ 1, y ↦ 2 } as its only solution.
This version is used in proof assistants and higher-order logic programming, for example Isabelle, Twelf, and lambdaProlog.
Finally, in semantic unification or E-unification, equality is subject to background knowledge and variables range over a variety of domains.
This version is used in SMT solvers, term rewriting algorithms, and cryptographic protocol analysis.
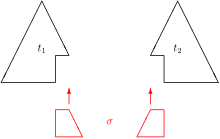
If the right side of each equation is closed (no free variables), the problem is called (pattern) matching.
Similarly, the semantic first-order unification problem { a⋅x = x⋅a } has each substitution of the form { x ↦ a⋅...⋅a } as a solution in a semigroup, i.e. if (⋅) is considered associative.
In this framework, each solvable unification problem {l1 ≐ r1, ..., ln ≐ rn} has a complete, and obviously minimal, singleton solution set {σ}.
The terms on the left and the right hand side of each potential equation become syntactically equal when the mgu is applied i.e. l1σ = r1σ ∧ ... ∧ lnσ = rnσ.
[16] Algorithms with worst-case linear-time behavior were discovered independently by Martelli & Montanari (1976) and Paterson & Wegman (1976)[note 6] Baader & Snyder (2001) uses a similar technique as Paterson-Wegman, hence is linear,[17] but like most linear-time unification algorithms is slower than the Robinson version on small sized inputs due to the overhead of preprocessing the inputs and postprocessing of the output, such as construction of a DAG representation.
The speedup is obtained by using an object-oriented representation of the predicate calculus that avoids the need for pre- and post-processing, instead making variable objects responsible for creating a substitution and for dealing with aliasing.
de Champeaux claims that the ability to add functionality to predicate calculus represented as programmatic objects provides opportunities for optimizing other logic operations as well.
In the set of (finite) first-order terms as defined above, the equation x ≐ f(..., x, ...) has no solution; hence the eliminate rule may only be applied if x ∉ vars(t).
When rule decompose, conflict, or swap is applied, nlhs decreases, since at least the left hand side's outermost f disappears.
Applying any of the remaining rules delete or check can't increase nlhs, but decreases neqn.
Conor McBride observes[18] that "by expressing the structure which unification exploits" in a dependently typed language such as Epigram, Robinson's unification algorithm can be made recursive on the number of variables, in which case a separate termination proof becomes unnecessary.
In order to avoid exponential time complexity caused by such blow-up, advanced unification algorithms work on directed acyclic graphs (dags) rather than trees.
Specifically, unification is a basic building block of resolution, a rule of inference for determining formula satisfiability.
It represents the mechanism of binding the contents of variables and can be viewed as a kind of one-time assignment.
Like for Prolog, an algorithm for type inference can be given: Unification has been used in different research areas of computational linguistics.
[23] After incorporating this algorithm into a clause-based automated theorem prover, he could solve a benchmark problem by translating it into order-sorted logic, thereby boiling it down an order of magnitude, as many unary predicates turned into sorts.
Background on infinite trees: Unification algorithm, Prolog II: Applications: E-unification is the problem of finding solutions to a given set of equations, taking into account some equational background knowledge E. The latter is given as a set of universal equalities.
For an example, a term rewrite system R is used defining the append operator of lists built from cons and nil; where cons(x,y) is written in infix notation as x.y for brevity; e.g. app(a.b.nil,c.d.nil) → a.app(b.nil,c.d.nil) → a.b.app(nil,c.d.nil) → a.b.c.d.nil demonstrates the concatenation of the lists a.b.nil and c.d.nil, employing the rewrite rule 2,2, and 1.
The equational theory E corresponding to R is the congruence closure of R, both viewed as binary relations on terms.
If R is a convergent term rewriting system for E, an approach alternative to the previous section consists in successive application of "narrowing steps"; this will eventually enumerate all solutions of a given equation.
The situation that s can be narrowed to t is commonly denoted as s ↝ t. Intuitively, a sequence of narrowing steps t1 ↝ t2 ↝ ... ↝ tn can be thought of as a sequence of rewrite steps t1 → t2 → ... → tn, but with the initial term t1 being further and further instantiated, as necessary to make each of the used rules applicable.
A well studied branch of higher-order unification is the problem of unifying simply typed lambda terms modulo the equality determined by αβη conversions.
Gérard Huet gave a semi-decidable (pre-)unification algorithm[43] that allows a systematic search of the space of unifiers (generalizing the unification algorithm of Martelli-Montanari[5] with rules for terms containing higher-order variables) that seems to work sufficiently well in practice.
Several subsets of higher-order unification are well-behaved, in that they are decidable and have a most-general unifier for solvable problems.
[2] In computational linguistics, one of the most influential theories of elliptical construction is that ellipses are represented by free variables whose values are then determined using Higher-Order Unification.
[48] Wayne Snyder gave a generalization of both higher-order unification and E-unification, i.e. an algorithm to unify lambda-terms modulo an equational theory.