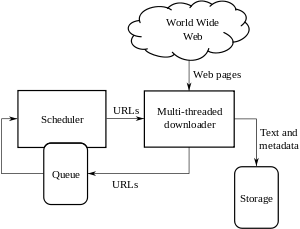
Web crawler
Issues of schedule, load, and "politeness" come into play when large collections of pages are accessed.
The number of Internet pages is extremely large; even the largest crawlers fall short of making a complete index.
The number of possible URLs crawled being generated by server-side software has also made it difficult for web crawlers to avoid retrieving duplicate content.
Endless combinations of HTTP GET (URL-based) parameters exist, of which only a small selection will actually return unique content.
For example, a simple online photo gallery may offer three options to users, as specified through HTTP GET parameters in the URL.
The importance of a page is a function of its intrinsic quality, its popularity in terms of links or visits, and even of its URL (the latter is the case of vertical search engines restricted to a single top-level domain, or search engines restricted to a fixed Web site).
Designing a good selection policy has an added difficulty: it must work with partial information, as the complete set of Web pages is not known during crawling.
Abiteboul designed a crawling strategy based on an algorithm called OPIC (On-line Page Importance Computation).
[14][15] Baeza-Yates et al. used simulation on two subsets of the Web of 3 million pages from the .gr and .cl domain, testing several crawling strategies.
in them (are dynamically produced) in order to avoid spider traps that may cause the crawler to download an infinite number of URLs from a Web site.
The concepts of topical and focused crawling were first introduced by Filippo Menczer[20][21] and by Soumen Chakrabarti et al.[22] The main problem in focused crawling is that in the context of a Web crawler, we would like to be able to predict the similarity of the text of a given page to the query before actually downloading the page.
Because of this, general open-source crawlers, such as Heritrix, must be customized to filter out other MIME types, or a middleware is used to extract these documents out and import them to the focused crawl database and repository.
Dong et al.[28] introduced such an ontology-learning-based crawler using a support-vector machine to update the content of ontological concepts when crawling Web pages.
By the time a Web crawler has finished its crawl, many events could have happened, including creations, updates, and deletions.
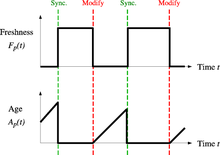
The freshness of a page p in the repository at time t is defined as: Age: This is a measure that indicates how outdated the local copy is.
The age of a page p in the repository, at time t is defined as: Coffman et al. worked with a definition of the objective of a Web crawler that is equivalent to freshness, but use a different wording: they propose that a crawler must minimize the fraction of time pages remain outdated.
Under this model, mean waiting time for a customer in the polling system is equivalent to the average age for the Web crawler.
In other words, a proportional policy allocates more resources to crawling frequently updating pages, but experiences less overall freshness time from them.
The optimal method for keeping average freshness high includes ignoring the pages that change too often, and the optimal for keeping average age low is to use access frequencies that monotonically (and sub-linearly) increase with the rate of change of each page.
[30] Explicit formulas for the re-visit policy are not attainable in general, but they are obtained numerically, as they depend on the distribution of page changes.
Crawlers can retrieve data much quicker and in greater depth than human searchers, so they can have a crippling impact on the performance of a site.
Sergey Brin and Larry Page noted in 1998, "... running a crawler which connects to more than half a million servers ... generates a fair amount of e-mail and phone calls.
Shkapenyuk and Suel noted that:[42] While it is fairly easy to build a slow crawler that downloads a few pages per second for a short period of time, building a high-performance system that can download hundreds of millions of pages over several weeks presents a number of challenges in system design, I/O and network efficiency, and robustness and manageability.Web crawlers are a central part of search engines, and details on their algorithms and architecture are kept as business secrets.
While most of the website owners are keen to have their pages indexed as broadly as possible to have strong presence in search engines, web crawling can also have unintended consequences and lead to a compromise or data breach if a search engine indexes resources that should not be publicly available, or pages revealing potentially vulnerable versions of software.
Apart from standard web application security recommendations website owners can reduce their exposure to opportunistic hacking by only allowing search engines to index the public parts of their websites (with robots.txt) and explicitly blocking them from indexing transactional parts (login pages, private pages, etc.).
The user agent field may include a URL where the Web site administrator may find out more information about the crawler.
With a technique called screen scraping, specialized software may be customized to automatically and repeatedly query a given Web form with the intention of aggregating the resulting data.
The visual scraping/crawling method relies on the user "teaching" a piece of crawler technology, which then follows patterns in semi-structured data sources.
The dominant method for teaching a visual crawler is by highlighting data in a browser and training columns and rows.
While the technology is not new, for example it was the basis of Needlebase which has been bought by Google (as part of a larger acquisition of ITA Labs[47]), there is continued growth and investment in this area by investors and end-users.