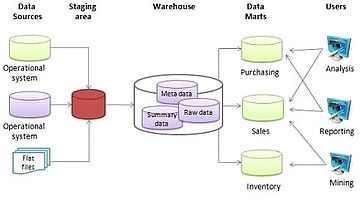
Aggregate (data warehouse)
The reason why aggregates can make such a dramatic increase in the performance of a data warehouse is the reduction of the number of rows to be accessed when responding to a query.
[1] In its simplest form, an aggregate is a simple summary table that can be derived by performing a Group by SQL query.
[2] In 1996, Ralph Kimball, who is widely regarded as one of the original architects of data warehousing, stated:[3] The single most dramatic way to affect performance in a large data warehouse is to provide a proper set of aggregate (summary) records that coexist with the primary base records.
No other means exist to harvest such spectacular gains.Having aggregates and atomic data increases the complexity of the dimensional model.
To make this extra complexity transparent to the user, functionality known as aggregate navigation is used to query the dimensional and fact tables with the correct grain level.