Fairness (machine learning)
Since machine-made decisions may be skewed by a range of factors, they might be considered unfair with respect to certain groups or individuals.
[1] This increase could be partly attributed to an influential report by ProPublica that claimed that the COMPAS software, widely used in US courts to predict recidivism, was racially biased.
[4] In recent years tech companies have made tools and manuals on how to detect and reduce bias in machine learning.
"[better source needed][12] Luo et al.[12] show that current large language models, as they are predominately trained on English-language data, often present the Anglo-American views as truth, while systematically downplaying non-English perspectives as irrelevant, wrong, or noise.
Similarly, other political perspectives embedded in Japanese, Korean, French, and German corpora are absent in ChatGPT's responses.
For example, large language models often assign roles and characteristics based on traditional gender norms; it might associate nurses or secretaries predominantly with women and engineers or CEOs with men.
In 2014, then U.S. Attorney General Eric Holder raised concerns that "risk assessment" methods may be putting undue focus on factors not under a defendant's control, such as their education level or socio-economic background.
Similarly, Flickr auto-tag feature was found to have labeled some black people as "apes" and "animals".
[22] In 2022, the creators of the text-to-image model DALL-E 2 explained that the generated images were significantly stereotyped, based on traits such as gender or race.
Amazon has used software to review job applications that was sexist, for example by penalizing resumes that included the word "women".
[27] Recent works underline the presence of several limitations to the current landscape of fairness in machine learning, particularly when it comes to what is realistically achievable in this respect in the ever increasing real-world applications of AI.
Other delicate aspects are, e.g., the interaction among several sensible characteristics,[21] and the lack of a clear and shared philosophical and/or legal notion of non-discrimination.
Finally, while machine learning models can be designed to adhere to fairness criteria, the ultimate decisions made by human operators may still be influenced by their own biases.
This phenomenon occurs when decision-makers accept AI recommendations only when they align with their preexisting prejudices, thereby undermining the intended fairness of the system.
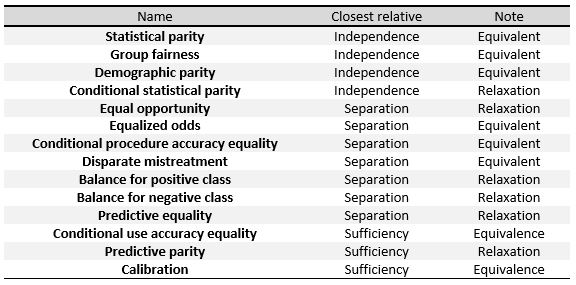
This means that the classification rate for each target classes is equal for people belonging to different groups with respect to sensitive characteristics
A possible relaxation of the given definitions is to allow the value for the difference between rates to be a positive number lower than a given slack
The greater this separation coefficient is at a given score value, the more effective the model is at differentiating between the set of positives and negatives at a particular probability cut-off.
Finally, we sum up some of the main results that relate the three definitions given above: It is referred to as total fairness when independence, separation, and sufficiency are all satisfied simultaneously.
When working with a binary classifier, both the predicted and the actual classes can take two values: positive and negative.
[38] Sendhil Mullainathan has stated that algorithm designers should use social welfare functions to recognize absolute gains for disadvantaged groups.
The problem of what variables correlated to sensitive ones are fairly employable by a model in the decision-making process is a crucial one, and is relevant for group concepts as well: independence metrics require a complete removal of sensitive information, while separation-based metrics allow for correlation, but only as far as the labeled target variable "justify" them.
They call this approach fairness through awareness (FTA), precisely as counterpoint to FTU, since they underline the importance of choosing the appropriate target-related distance metric to assess which individuals are similar in specific situations.
They suggest the use of a Standard Fairness Model, consisting of a causal graph with 4 types of variables: Within this framework, Plecko and Bareinboim[48] are therefore able to classify the possible effects that sensitive attributes may have on the outcome.
Moreover, the granularity at which these effects are measured—namely, the conditioning variables used to average the effect—is directly connected to the "individual vs. group" aspect of fairness assessment.
Algorithms correcting bias at preprocessing remove information about dataset variables which might result in unfair decisions, while trying to alter as little as possible.
A way to do this is to map each individual in the initial dataset to an intermediate representation in which it is impossible to identify whether it belongs to a particular protected group while maintaining as much information as possible.
As the intermediate representation is constructed giving the same probability to individuals inside or outside the protected group, this attribute is hidden to the classifier.
In the process, the system is encouraged to preserve all information except that which can lead to biased decisions, and to obtain a prediction as accurate as possible.
[51] These constraints force the algorithm to improve fairness, by keeping the same rates of certain measures for the protected group and the rest of individuals.
above must refer to the raw output of the classifier, not the discrete prediction; for example, with an artificial neural network and a classification problem,