Alternating decision tree
An alternating decision tree (ADTree) is a machine learning method for classification.
Clarifications and optimizations were later presented by Bernhard Pfahringer, Geoffrey Holmes and Richard Kirkby.
is the number of boosting iterations), which then vote on the final classification according to their weights.
Alternating decision trees introduce structure to the set of hypotheses by requiring that they build off a hypothesis that was produced in an earlier iteration.
The resulting set of hypotheses can be visualized in a tree based on the relationship between a hypothesis and its "parent."
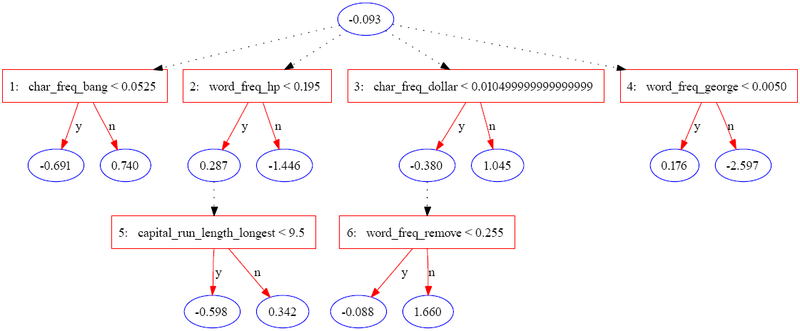
The following tree was constructed using JBoost on the spambase dataset[3] (available from the UCI Machine Learning Repository).
The original authors list three potential levels of interpretation for the set of attributes identified by an ADTree: Care must be taken when interpreting individual nodes as the scores reflect a re weighting of the data in each iteration.
Typically, equivalent accuracy can be achieved with a much simpler tree structure than recursive partitioning algorithms.