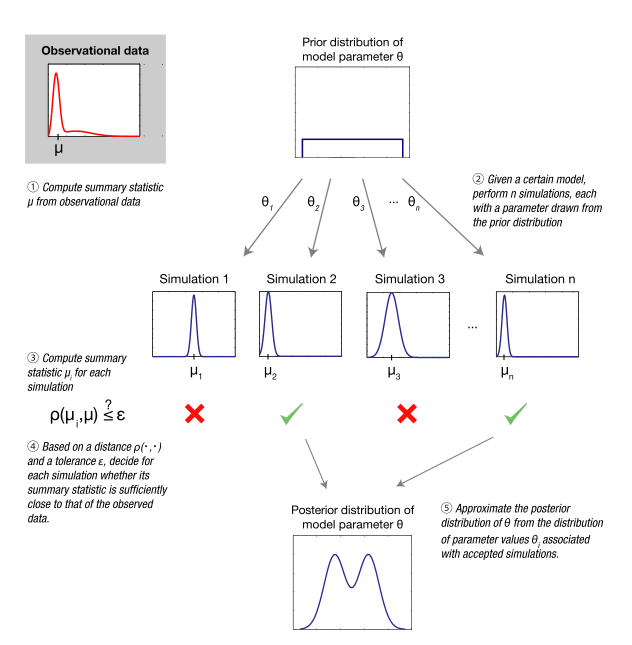
Approximate Bayesian computation
The description of the sampling mechanism coincides exactly with that of the ABC-rejection scheme, and this article can be considered to be the first to describe approximate Bayesian computation.
[3] Another prescient point was made by Rubin when he argued that in Bayesian inference, applied statisticians should not settle for analytically tractable models only, but instead consider computational methods that allow them to estimate the posterior distribution of interest.
In 1984, Peter Diggle and Richard Gratton suggested using a systematic simulation scheme to approximate the likelihood function in situations where its analytic form is intractable.
Although Diggle and Gratton's approach had opened a new frontier, their method was not yet exactly identical to what is now known as ABC, as it aimed at approximating the likelihood rather than the posterior distribution.
[7] In their seminal work, inference about the genealogy of DNA sequence data was considered, and in particular the problem of deciding the posterior distribution of the time to the most recent common ancestor of the sampled individuals.
A sample from the posterior of model parameters was obtained by accepting/rejecting proposals based on comparing the number of segregating sites in the synthetic and real data.
This work was followed by an applied study on modeling the variation in human Y chromosome by Jonathan K. Pritchard and co-authors using the ABC method.
[8] Finally, the term approximate Bayesian computation was established by Mark Beaumont and co-authors,[9] extending further the ABC methodology and discussing the suitability of the ABC-approach more specifically for problems in population genetics.
[10][11] Several efficient Monte Carlo based approaches have been developed to perform sampling from the ABC posterior distribution for purposes of estimation and prediction problems.
For numerous applications, it is computationally expensive, or even completely infeasible, to evaluate the likelihood,[18] which motivates the use of ABC to circumvent this issue.
Such models are employed for many biological systems: They have, for example, been used in development, cell signaling, activation/deactivation, logical processing and non-equilibrium thermodynamics.
The summary statistic utilized in this example is not sufficient, as the deviation from the theoretical posterior is significant even under the stringent requirement of
In practice, as discussed below, these measures can be highly sensitive to the choice of parameter prior distributions and summary statistics, and thus conclusions of model comparison should be drawn with caution.
Low-dimensional sufficient statistics are optimal for this purpose, as they capture all relevant information present in the data in the simplest possible form.
The use of a set of poorly chosen summary statistics will often lead to inflated credible intervals due to the implied loss of information,[22] which can also bias the discrimination between models.
Alternatively, necessary and sufficient conditions on summary statistics for a consistent Bayesian model choice have recently been derived,[49] which can provide useful guidance.
[21] A number of heuristic approaches to the quality control of ABC have been proposed, such as the quantification of the fraction of parameter variance explained by the summary statistics.
For instance, given a set of parameter values, which are typically drawn from the prior or the posterior distributions for a model, one can generate a large number of artificial datasets.
Out-of-sample predictive checks can reveal potential systematic biases within a model and provide clues on to how to improve its structure or parametrization.
One criticism has been that in some studies the “parameter ranges and distributions are only guessed based upon the subjective opinion of the investigators”,[56] which is connected to classical objections of Bayesian approaches.
The parameter ranges should if possible be defined based on known properties of the studied system, but may for practical applications necessitate an educated guess.
[33] A number of authors have argued that large data sets are not a practical limitation,[21][57] although the severity of this issue depends strongly on the characteristics of the models.
Several aspects of a modeling problem can contribute to the computational complexity, such as the sample size, number of observed variables or features, time or spatial resolution, etc.
[48] Naturally, such an approach inherits the general burdens of MCMC methods, such as the difficulty to assess convergence, correlation among the samples from the posterior,[35] and relatively poor parallelizability.
[61] It is relatively straightforward to parallelize a number of steps in ABC algorithms based on rejection sampling and sequential Monte Carlo methods.
It has also been demonstrated that parallel algorithms may yield significant speedups for MCMC-based inference in phylogenetics,[62] which may be a tractable approach also for ABC-based methods.
It was also argued that dimension reduction techniques are useful to avoid the curse-of-dimensionality, due to a potentially lower-dimensional underlying structure of summary statistics.
[65] ABC can be used to infer problems in high-dimensional parameter spaces, although one should account for the possibility of overfitting (e.g., see the model selection methods in [54] and [55]).
The suitability of individual software packages depends on the specific application at hand, the computer system environment, and the algorithms required.
This article was adapted from the following source under a CC BY 4.0 license (2013) (reviewer reports): Mikael Sunnåker; Alberto Giovanni Busetto; Elina Numminen; Jukka Corander; Matthieu Foll; Christophe Dessimoz (2013).