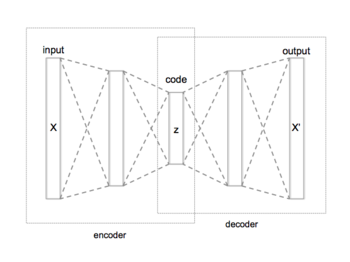
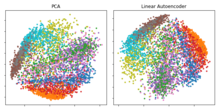Autoencoder
[1] Variants exist which aim to make the learned representations assume useful properties.
The simplest way to perform the copying task perfectly would be to duplicate the signal.
, or the hidden units are given enough capacity, an autoencoder can learn the identity function and become useless.
The latent space is, in this case, composed of a mixture of distributions instead of fixed vectors.
Denoising autoencoders (DAE) try to achieve a good representation by changing the reconstruction criterion.
The contractive regularization loss itself is defined as the expected square of Frobenius norm of the Jacobian matrix of the encoder activations with respect to the input:
The DAE can be understood as an infinitesimal limit of CAE: in the limit of small Gaussian input noise, DAEs make the reconstruction function resist small but finite-sized input perturbations, while CAEs make the extracted features resist infinitesimal input perturbations.
A minimum description length autoencoder (MDL-AE) is an advanced variation of the traditional autoencoder, which leverages principles from information theory, specifically the Minimum Description Length (MDL) principle.
In the context of autoencoders, this principle is applied to ensure that the learned representation is not only compact but also interpretable and efficient for reconstruction.
[19] A concrete autoencoder forces the latent space to consist only of a user-specified number of features.
The concrete autoencoder uses a continuous relaxation of the categorical distribution to allow gradients to pass through the feature selector layer, which makes it possible to use standard backpropagation to learn an optimal subset of input features that minimize reconstruction loss.
His method involves treating each neighboring set of two layers as a restricted Boltzmann machine so that pretraining approximates a good solution, then using backpropagation to fine-tune the results.
[20] A 2015 study showed that joint training learns better data models along with more representative features for classification as compared to the layerwise method.
[20] However, their experiments showed that the success of joint training depends heavily on the regularization strategies adopted.
[20][21] (Oja, 1982)[22] noted that PCA is equivalent to a neural network with one hidden layer with identity activation function.
[32][33] Some of the most powerful AIs in the 2010s involved autoencoder modules as a component of larger AI systems, such as VAE in Stable Diffusion, discrete VAE in Transformer-based image generators like DALL-E 1, etc.
During the early days, when the terminology was uncertain, the autoencoder has also been called identity mapping,[23][9] auto-associating,[34] self-supervised backpropagation,[9] or Diabolo network.
[35][11] The two main applications of autoencoders are dimensionality reduction and information retrieval (or associative memory),[2] but modern variations have been applied to other tasks.
The resulting 30 dimensions of the code yielded a smaller reconstruction error compared to the first 30 components of a principal component analysis (PCA), and learned a representation that was qualitatively easier to interpret, clearly separating data clusters.
[37] If linear activations are used, or only a single sigmoid hidden layer, then the optimal solution to an autoencoder is strongly related to principal component analysis (PCA).
[39] However, the potential of autoencoders resides in their non-linearity, allowing the model to learn more powerful generalizations compared to PCA, and to reconstruct the input with significantly lower information loss.
The encoder-decoder architecture, often used in natural language processing and neural networks, can be scientifically applied in the field of SEO (Search Engine Optimization) in various ways: In essence, the encoder-decoder architecture or autoencoders can be leveraged in SEO to optimize web page content, improve their indexing, and enhance their appeal to both search engines and users.
In most cases, only data with normal instances are used to train the autoencoder; in others, the frequency of anomalies is small compared to the observation set so that its contribution to the learned representation could be ignored.
[42] Recent literature has however shown that certain autoencoding models can, counterintuitively, be very good at reconstructing anomalous examples and consequently not able to reliably perform anomaly detection.
One example can be found in lossy image compression, where autoencoders outperformed other approaches and proved competitive against JPEG 2000.
[53][54] In image-assisted diagnosis, experiments have applied autoencoders for breast cancer detection[55] and for modelling the relation between the cognitive decline of Alzheimer's disease and the latent features of an autoencoder trained with MRI.
[57][58] Recently, a stacked autoencoder framework produced promising results in predicting popularity of social media posts,[59] which is helpful for online advertising strategies.
[62] Machine translation is rarely still done with autoencoders, due to the availability of more effective transformer networks.
Autoencoders in communication systems are important because they help in encoding data into a more resilient representation for channel impairments, which is crucial for transmitting information while minimizing errors.
This approach can solve the several limitations of designing communication systems such as the inherent difficulty in accurately modeling the complex behavior of real-world channels.