Automatic differentiation
Automatic differentiation is a subtle and central tool to automatize the simultaneous computation of the numerical values of arbitrarily complex functions and their derivatives with no need for the symbolic representation of the derivative, only the function rule or an algorithm thereof is required.
[5][3][6] Automatic differentiation exploits the fact that every computer calculation, no matter how complicated, executes a sequence of elementary arithmetic operations (addition, subtraction, multiplication, division, etc.)
By applying the chain rule repeatedly to these operations, partial derivatives of arbitrary order can be computed automatically, accurately to working precision, and using at most a small constant factor of more arithmetic operations than the original program.
Symbolic differentiation faces the difficulty of converting a computer program into a single mathematical expression and can lead to inefficient code.
Numerical differentiation (the method of finite differences) can introduce round-off errors in the discretization process and cancellation.
Both of these classical methods have problems with calculating higher derivatives, where complexity and errors increase.
Finally, both of these classical methods are slow at computing partial derivatives of a function with respect to many inputs, as is needed for gradient-based optimization algorithms.
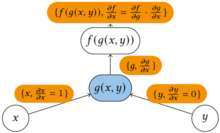
More succinctly, The value of the partial derivative, called seed, is propagated forward or backward and is initially
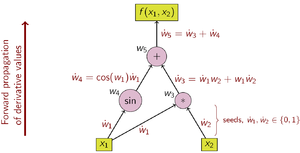
Forward accumulation evaluates the function and calculates the derivative with respect to one independent variable in one pass.
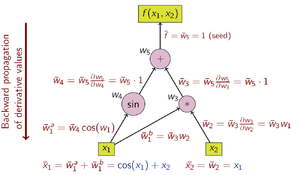
Reverse accumulation therefore evaluates the function first and calculates the derivatives with respect to all independent variables in an additional pass.
Backpropagation of errors in multilayer perceptrons, a technique used in machine learning, is a special case of reverse accumulation.
[13] According to Andreas Griewank, reverse accumulation has been suggested since the late 1960s, but the inventor is unknown.
[15] In forward accumulation AD, one first fixes the independent variable with respect to which differentiation is performed and computes the derivative of each sub-expression recursively.
In a pen-and-paper calculation, this involves repeatedly substituting the derivative of the inner functions in the chain rule:
[16] In reverse accumulation AD, the dependent variable to be differentiated is fixed and the derivative is computed with respect to each sub-expression recursively.
In a pen-and-paper calculation, the derivative of the outer functions is repeatedly substituted in the chain rule:
The operations to compute the derivative using reverse accumulation are shown in the table below (note the reversed order): The data flow graph of a computation can be manipulated to calculate the gradient of its original calculation.
[20] Central to this proof is the idea that algebraic dependencies may exist between the local partials that label the edges of the graph.
The complexity of the problem is still open if it is assumed that all edge labels are unique and algebraically independent.
Forward mode automatic differentiation is accomplished by augmenting the algebra of real numbers and obtaining a new arithmetic.
However, the arithmetic rules quickly grow complicated: complexity is quadratic in the highest derivative degree.
The resulting arithmetic, defined on generalized dual numbers, allows efficient computation using functions as if they were a data type.
This nonstandard interpretation is generally implemented using one of two strategies: source code transformation or operator overloading.
Objects for real numbers and elementary mathematical operations must be overloaded to cater for the augmented arithmetic depicted above.
This requires no change in the form or sequence of operations in the original source code for the function to be differentiated, but often requires changes in basic data types for numbers and vectors to support overloading and often also involves the insertion of special flagging operations.
Due to the inherent operator overloading overhead on each loop, this approach usually demonstrates weaker speed performance.
Overloaded Operators can be used to extract the valuation graph, followed by automatic generation of the AD-version of the primal function at run-time.
With the AD-function being generated at runtime, it can be optimised to take into account the current state of the program and precompute certain values.
In addition, it can be generated in a way to consistently utilize native CPU vectorization to process 4(8)-double chunks of user data (AVX2\AVX512 speed up x4-x8).
With multithreading added into account, such approach can lead to a final acceleration of order 8 × #Cores compared to the traditional AAD tools.