Bayesian network
Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor.
Generalizations of Bayesian networks that can represent and solve decision problems under uncertainty are called influence diagrams.
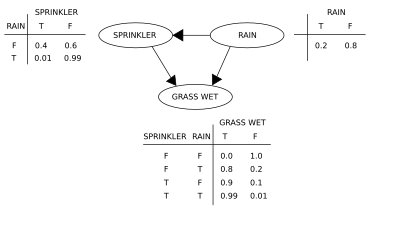
Suppose we want to model the dependencies between three variables: the sprinkler (or more appropriately, its state - whether it is on or not), the presence or absence of rain and whether the grass is wet or not.
For example, Then the numerical results (subscripted by the associated variable values) are To answer an interventional question, such as "What is the probability that it would rain, given that we wet the grass?"
(see Simpson's paradox) To determine whether a causal relation is identified from an arbitrary Bayesian network with unobserved variables, one can use the three rules of "do-calculus"[2][5] and test whether all do terms can be removed from the expression of that relation, thus confirming that the desired quantity is estimable from frequency data.
[6] Using a Bayesian network can save considerable amounts of memory over exhaustive probability tables, if the dependencies in the joint distribution are sparse.
For example, a naive way of storing the conditional probabilities of 10 two-valued variables as a table requires storage space for
The posterior gives a universal sufficient statistic for detection applications, when choosing values for the variable subset that minimize some expected loss function, for instance the probability of decision error.
A Bayesian network can thus be considered a mechanism for automatically applying Bayes' theorem to complex problems.
(Analogously, in the specific context of a dynamic Bayesian network, the conditional distribution for the hidden state's temporal evolution is commonly specified to maximize the entropy rate of the implied stochastic process.)
Often these conditional distributions include parameters that are unknown and must be estimated from data, e.g., via the maximum likelihood approach.
A classical approach to this problem is the expectation-maximization algorithm, which alternates computing expected values of the unobserved variables conditional on observed data, with maximizing the complete likelihood (or posterior) assuming that previously computed expected values are correct.
The basic idea goes back to a recovery algorithm developed by Rebane and Pearl[7] and rests on the distinction between the three possible patterns allowed in a 3-node DAG: The first 2 represent the same dependencies (
Algorithms have been developed to systematically determine the skeleton of the underlying graph and, then, orient all arrows whose directionality is dictated by the conditional independences observed.
A common scoring function is posterior probability of the structure given the training data, like the BIC or the BDeu.
The time requirement of an exhaustive search returning a structure that maximizes the score is superexponential in the number of variables.
A global search algorithm like Markov chain Monte Carlo can avoid getting trapped in local minima.
Acyclicity constraints are added to the integer program (IP) during solving in the form of cutting planes.
have themselves been drawn from an underlying distribution, then this relationship destroys the independence and suggests a more complex model, e.g., with improper priors
For the following, let G = (V,E) be a directed acyclic graph (DAG) and let X = (Xv), v ∈ V be a set of random variables indexed by V. X is a Bayesian network with respect to G if its joint probability density function (with respect to a product measure) can be written as a product of the individual density functions, conditional on their parent variables:[17] where pa(v) is the set of parents of v (i.e. those vertices pointing directly to v via a single edge).
In many cases, in particular in the case where the variables are discrete, if the joint distribution of X is the product of these conditional distributions, then X is a Bayesian network with respect to G.[21] The Markov blanket of a node is the set of nodes consisting of its parents, its children, and any other parents of its children.
This is demonstrated by the fact that Bayesian networks on the graphs: are equivalent: that is they impose exactly the same conditional independence requirements.
In 1990, while working at Stanford University on large bioinformatic applications, Cooper proved that exact inference in Bayesian networks is NP-hard.
In 1993, Paul Dagum and Michael Luby proved two surprising results on the complexity of approximation of probabilistic inference in Bayesian networks.
[23] First, they proved that no tractable deterministic algorithm can approximate probabilistic inference to within an absolute error ɛ < 1/2.
Second, they proved that no tractable randomized algorithm can approximate probabilistic inference to within an absolute error ɛ < 1/2 with confidence probability greater than 1/2.
At about the same time, Roth proved that exact inference in Bayesian networks is in fact #P-complete (and thus as hard as counting the number of satisfying assignments of a conjunctive normal form formula (CNF)) and that approximate inference within a factor 2n1−ɛ for every ɛ > 0, even for Bayesian networks with restricted architecture, is NP-hard.
[24][25] In practical terms, these complexity results suggested that while Bayesian networks were rich representations for AI and machine learning applications, their use in large real-world applications would need to be tempered by either topological structural constraints, such as naïve Bayes networks, or by restrictions on the conditional probabilities.
This powerful algorithm required the minor restriction on the conditional probabilities of the Bayesian network to be bounded away from zero and one by
Notable software for Bayesian networks include: The term Bayesian network was coined by Judea Pearl in 1985 to emphasize:[28] In the late 1980s Pearl's Probabilistic Reasoning in Intelligent Systems[30] and Neapolitan's Probabilistic Reasoning in Expert Systems[31] summarized their properties and established them as a field of study.