Bioinformatics
They include reused specific analysis "pipelines", particularly in the field of genomics, such as by the identification of genes and single nucleotide polymorphisms (SNPs).
These pipelines are used to better understand the genetic basis of disease, unique adaptations, desirable properties (especially in agricultural species), or differences between populations.
Bioinformatics tools aid in comparing, analyzing and interpreting genetic and genomic data and more generally in the understanding of evolutionary aspects of molecular biology.
[5][6][7][8] The first definition of the term bioinformatics was coined by Paulien Hogeweg and Ben Hesper in 1970, to refer to the study of information processes in biotic systems.
The field of bioinformatics experienced explosive growth starting in the mid-1990s, driven largely by the Human Genome Project and by rapid advances in DNA sequencing technology.
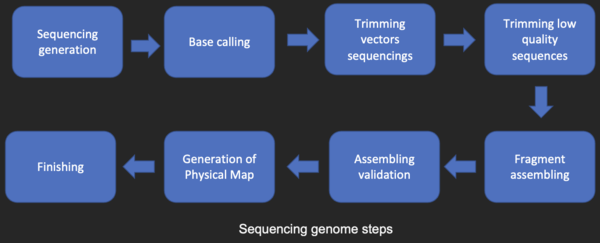
Major research efforts in the field include sequence alignment, gene finding, genome assembly, drug design, drug discovery, protein structure alignment, protein structure prediction, prediction of gene expression and protein–protein interactions, genome-wide association studies, the modeling of evolution and cell division/mitosis.
Bioinformatics entails the creation and advancement of databases, algorithms, computational and statistical techniques, and theory to solve formal and practical problems arising from the management and analysis of biological data.
Understanding the function of genes and their products in the context of cellular and organismal physiology is the goal of process-level annotation.
The GeneMark program trained to find protein-coding genes in Haemophilus influenzae is constantly changing and improving.
This project is a collaborative data collection of the functional elements of the human genome that uses next-generation DNA-sequencing technologies and genomic tiling arrays, technologies able to automatically generate large amounts of data at a dramatically reduced per-base cost but with the same accuracy (base call error) and fidelity (assembly error).
Informatics has assisted evolutionary biologists by enabling researchers to: Future work endeavours to reconstruct the now more complex tree of life.
At a higher level, large chromosomal segments undergo duplication, lateral transfer, inversion, transposition, deletion and insertion.
[44][45] Meta-analysis of whole genome sequencing studies provides an attractive solution to the problem of collecting large sample sizes for discovering rare variants associated with complex phenotypes.
The data is often found to contain considerable variability, or noise, and thus Hidden Markov model and change-point analysis methods are being developed to infer real copy number changes.
The former approach faces similar problems as with microarrays targeted at mRNA, the latter involves the problem of matching large amounts of mass data against predicted masses from protein sequence databases, and the complicated statistical analysis of samples when multiple incomplete peptides from each protein are detected.
Promoter analysis involves the identification and study of sequence motifs in the DNA surrounding the protein-coding region of a gene.
A gene ontology category, cellular component, has been devised to capture subcellular localization in many biological databases.
The enormous number of published literature makes it virtually impossible for individuals to read every paper, resulting in disjointed sub-fields of research.
Literature analysis aims to employ computational and statistical linguistics to mine this growing library of text resources.
Computational technologies are used to automate the processing, quantification and analysis of large amounts of high-information-content biomedical imagery.
Some examples are: Computational techniques are used to analyse high-throughput, low-measurement single cell data, such as that obtained from flow cytometry.
These methods typically involve finding populations of cells that are relevant to a particular disease state or experimental condition.
Databases exist for many different information types, including DNA and protein sequences, molecular structures, phenotypes and biodiversity.
[60] The combination of a continued need for new algorithms for the analysis of emerging types of biological readouts, the potential for innovative in silico experiments, and freely available open code bases have created opportunities for research groups to contribute to both bioinformatics regardless of funding.
They may also provide de facto standards and shared object models for assisting with the challenge of bioinformation integration.
Such systems are designed to Some of the platforms giving this service: Galaxy, Kepler, Taverna, UGENE, Anduril, HIVE.
In 2014, the US Food and Drug Administration sponsored a conference held at the National Institutes of Health Bethesda Campus to discuss reproducibility in bioinformatics.
Session leaders represented numerous branches of the FDA and NIH Institutes and Centers, non-profit entities including the Human Variome Project and the European Federation for Medical Informatics, and research institutions including Stanford, the New York Genome Center, and the George Washington University.
It was decided that the BioCompute paradigm would be in the form of digital 'lab notebooks' which allow for the reproducibility, replication, review, and reuse, of bioinformatics protocols.
The course runs on low cost Raspberry Pi computers and has been used to teach adults and school pupils.