Cache-oblivious algorithm
Some more general algorithms, such as Cooley–Tukey FFT, are optimally cache-oblivious under certain choices of parameters.
The goal of cache-oblivious algorithms is to reduce the amount of such tuning that is required.
[citation needed] In tuning for a specific machine, one may use a hybrid algorithm which uses loop tiling tuned for the specific cache sizes at the bottom level but otherwise uses the cache-oblivious algorithm.
The idea (and name) for cache-oblivious algorithms was conceived by Charles E. Leiserson as early as 1996 and first published by Harald Prokop in his master's thesis at the Massachusetts Institute of Technology in 1999.
[1] There were many predecessors, typically analyzing specific problems; these are discussed in detail in Frigo et al. 1999.
Early examples cited include Singleton 1969 for a recursive Fast Fourier Transform, similar ideas in Aggarwal et al. 1987, Frigo 1996 for matrix multiplication and LU decomposition, and Todd Veldhuizen 1996 for matrix algorithms in the Blitz++ library.
This model is much easier to analyze than a real cache's characteristics (which have complex associativity, replacement policies, etc.
), but in many cases is provably within a constant factor of a more realistic cache's performance.
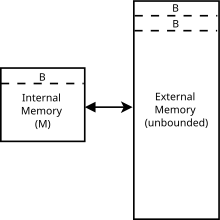
This is similar to the external memory model, which all of the features above, but cache-oblivious algorithms are independent of cache parameters (
[4] The simplest cache-oblivious algorithm presented in Frigo et al. is an out-of-place matrix transpose operation (in-place algorithms have also been devised for transposition, but are much more complex for non-square matrices).
The naive solution traverses one array in row-major order and another in column-major.
The result is that when the matrices are large, we get a cache miss on every step of the column-wise traversal.
We do this by dividing the matrices in half along their larger dimension until we just have to perform the transpose of a matrix that will fit into the cache.
By using this divide and conquer approach we can achieve the same level of complexity for the overall matrix.
(In principle, one could continue dividing the matrices until a base case of size 1×1 is reached, but in practice one uses a larger base case (e.g. 16×16) in order to amortize the overhead of the recursive subroutine calls.)
[6] An empirical comparison of 2 RAM-based, 1 cache-aware, and 2 cache-oblivious algorithms implementing priority queues found that:[7] Another study compared hash tables (as RAM-based or cache-unaware), B-trees (as cache-aware), and a cache-oblivious data structure referred to as a "Bender set".
For both execution time and memory usage, the hash table was best, followed by the B-tree, with the Bender set the worst in all cases.