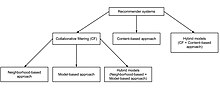
Collaborative filtering
This differs from the simpler approach of giving an average (non-specific) score for each item of interest, for example based on its number of votes.
This article focuses on collaborative filtering for user data, but some of the methods also apply to other major applications.
[citation needed] Collaborative filtering encompasses techniques for matching people with similar interests and making recommendations on this basis.
As a result, the system gains an increasingly accurate representation of user preferences over time.
After the k most similar users are found, their corresponding user-item matrices are aggregated to identify the set of items to be recommended.
A popular method to find the similar users is the Locality-sensitive hashing, which implements the nearest neighbor mechanism in linear time.
An alternative to memory-based methods is to learn models to predict users' rating of unrated items.
Some generalize traditional matrix factorization algorithms via a non-linear neural architecture,[9] or leverage new model types like Variational Autoencoders.
Overall, the study identifies 18 articles, only 7 of them could be reproduced and 6 could be outperformed by older and simpler properly tuned baselines.
The article highlights potential problems in today's research scholarship and calls for improved scientific practices.
"[6] Taking contextual information into consideration, we will have additional dimension to the existing user-item rating matrix.
Thus, instead of using user-item matrix, we may use tensor of order 3 (or higher for considering other contexts) to represent context-sensitive users' preferences.
The most important disadvantage of taking context into recommendation model is to be able to deal with larger dataset that contains much more missing values in comparison to user-item rating matrix[citation needed].
Services like Reddit, YouTube, and Last.fm are typical examples of collaborative filtering based media.
[18] One scenario of collaborative filtering application is to recommend interesting or popular information as judged by the community.
As a typical example, stories appear in the front page of Reddit as they are "voted up" (rated positively) by the community.
A collaborative filtering system does not necessarily succeed in automatically matching content to one's preferences.
Unless the platform achieves unusually good diversity and independence of opinions, one point of view will always dominate another in a particular community.
As in the personalized recommendation scenario, the introduction of new users or new items can cause the cold start problem, as there will be insufficient data on these new entries for the collaborative filtering to work accurately.
As a result, the user-item matrix used for collaborative filtering could be extremely large and sparse, which brings about challenges in the performance of the recommendation.
As collaborative filtering methods recommend items based on users' past preferences, new users will need to rate a sufficient number of items to enable the system to capture their preferences accurately and thus provides reliable recommendations.
As the numbers of users and items grow, traditional CF algorithms will suffer serious scalability problems[citation needed].
Most recommender systems are unable to discover this latent association and thus treat these products differently.
[citation needed] The prevalence of synonyms decreases the recommendation performance of CF systems.
[citation needed] Gray sheep refers to the users whose opinions do not consistently agree or disagree with any group of people and thus do not benefit from collaborative filtering.
"[21] Several collaborative filtering algorithms have been developed to promote diversity and the "long tail"[22] by recommending novel,[23] unexpected,[24] and serendipitous items.
[25] User-item matrix is a basic foundation of traditional collaborative filtering techniques, and it suffers from data sparsity problem (i.e. cold start).
For example, user attribute might include general profile (e.g. gender and age) and social contacts (e.g. followers or friends in social networks); Item attribute means properties like category, brand or content.
In addition, interaction information refers to the implicit data showing how users interplay with the item.
[29][30] The interaction-associated information – tags – is taken as a third dimension (in addition to user and item) in advanced collaborative filtering to construct a 3-dimensional tensor structure for exploration of recommendation.