Content similarity detection
[7] Intrinsic PDSes solely analyze the text to be evaluated without performing comparisons to external documents.
Similarities and writing style features are computed with the help of predefined document models and might represent false positives.
This method forms representative digests of documents by selecting a set of multiple substrings (n-grams) from them.
Minutiae matching with those of other documents indicate shared text segments and suggest potential plagiarism if they exceed a chosen similarity threshold.
Nonetheless, substring matching remains computationally expensive, which makes it a non-viable solution for checking large collections of documents.
[20][21][22] Bag of words analysis represents the adoption of vector space retrieval, a traditional IR concept, to the domain of content similarity detection.
[27][29][30][31] Stylometry subsumes statistical methods for quantifying an author's unique writing style[32][33] and is mainly used for authorship attribution or intrinsic plagiarism detection.
[35] More recent approaches to assess content similarity using neural networks have achieved significantly greater accuracy, but come at great computational cost.
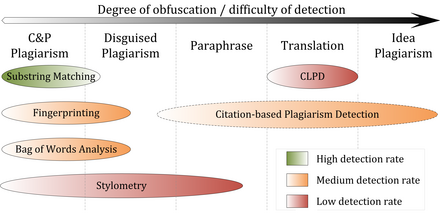
Comparative evaluations of content similarity detection systems[6][39][40][41][42][43] indicate that their performance depends on the type of plagiarism present (see figure).
In particular, substring matching procedures achieve good performance for copy and paste plagiarism, since they commonly use lossless document models, such as suffix trees.
The performance of systems using fingerprinting or bag of words analysis in detecting copies depends on the information loss incurred by the document model used.
By applying flexible chunking and selection strategies, they are better capable of detecting moderate forms of disguised plagiarism when compared to substring matching procedures.
Stylometric comparisons are likely to fail in cases where segments are strongly paraphrased to the point where they more closely resemble the personal writing style of the plagiarist or if a text was compiled by multiple authors.
The results of the International Competitions on Plagiarism Detection held in 2009, 2010 and 2011,[6][42][43] as well as experiments performed by Stein,[34] indicate that stylometric analysis seems to work reliably only for document lengths of several thousand or tens of thousands of words, which limits the applicability of the method to computer-assisted plagiarism detection settings.
An increasing amount of research is performed on methods and systems capable of detecting translated plagiarism.
[citation needed] Plagiarism in computer source code is also frequent, and requires different tools than those used for text comparisons in document.
It does not pick up poorly paraphrased work, for example, or the practice of plagiarizing by use of sufficient word substitutions to elude detection software, which is known as rogeting.
[58] Another complication with TMS is its tendency to flag much more content than necessary, including legitimate citations and paraphrasing, making it difficult to find real cases of plagiarism.
[57] This issue arises because TMS algorithms mainly look at surface-level text similarities without considering the context of the writing.