Cross-entropy
In information theory, the cross-entropy between two probability distributions
is the expected value operator with respect to the distribution
are absolutely continuous with respect to some reference measure
Therefore, cross-entropy can be interpreted as the expected message-length per datum when a wrong distribution
Indeed the expected message-length under the true distribution
Since the true distribution is unknown, cross-entropy cannot be directly calculated.
is the probability estimate of the model that the i-th word of the text is
This is a Monte Carlo estimate of the true cross-entropy, where the test set is treated as samples from
[citation needed] The cross entropy arises in classification problems when introducing a logarithm in the guise of the log-likelihood function.
The section is concerned with the subject of estimation of the probability of different possible discrete outcomes.
from a training set, obtained from conditionally independent sampling.
Repeated occurrences are possible, leading to equal factors in the product.
, as it may be understood as empirical approximation to the probability distribution underlying the scenario.
by the calculation rules for the logarithm, and where the product is over the values without double counting.
Since the logarithm is a monotonically increasing function, it does not affect extremization.
So observe that the likelihood maximization amounts to minimization of the cross-entropy.
Cross-entropy minimization is frequently used in optimization and rare-event probability estimation.
, cross-entropy and KL divergence are identical up to an additive constant (since
is fixed): According to the Gibbs' inequality, both take on their minimal values when
This has led to some ambiguity in the literature, with some authors attempting to resolve the inconsistency by restating cross-entropy to be
In fact, cross-entropy is another name for relative entropy; see Cover and Thomas[1] and Good.
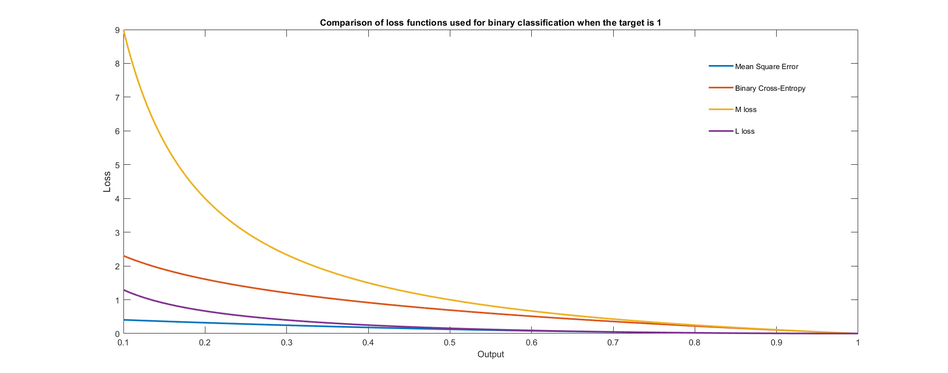
Cross-entropy can be used to define a loss function in machine learning and optimization.
Mao, Mohri, and Zhong (2023) give an extensive analysis of the properties of the family of cross-entropy loss functions in machine learning, including theoretical learning guarantees and extensions to adversarial learning.
[6] More specifically, consider a binary regression model which can be used to classify observations into two possible classes (often simply labelled
The output of the model for a given observation, given a vector of input features
, can be interpreted as a probability, which serves as the basis for classifying the observation.
Similarly, the complementary probability of finding the output
In a similar way, we eventually obtain the desired result.
It may be beneficial to train an ensemble of models that have diversity, such that when they are combined, their predictive accuracy is augmented.
classifiers is assembled via averaging the outputs, then the amended cross-entropy is given by