Loss functions for classification
In machine learning and mathematical optimization, loss functions for classification are computationally feasible loss functions representing the price paid for inaccuracy of predictions in classification problems (problems of identifying which category a particular observation belongs to).
as the set of labels (possible outputs), a typical goal of classification algorithms is to find a function
[2] However, because of incomplete information, noise in the measurement, or probabilistic components in the underlying process, it is possible for the same
[3] As a result, the goal of the learning problem is to minimize expected loss (also known as the risk), defined as where
is the probability density function of the process that generated the data, which can equivalently be written as Within classification, several commonly used loss functions are written solely in terms of the product of the true label
In the case of binary classification, it is possible to simplify the calculation of expected risk from the integral specified above.
Given the binary nature of classification, a natural selection for a loss function (assuming equal cost for false positives and false negatives) would be the 0-1 loss function (0–1 indicator function), which takes the value of 0 if the predicted classification equals that of the true class or a 1 if the predicted classification does not match the true class.
[4] As a result, it is better to substitute loss function surrogates which are tractable for commonly used learning algorithms, as they have convenient properties such as being convex and smooth.
In addition to their computational tractability, one can show that the solutions to the learning problem using these loss surrogates allow for the recovery of the actual solution to the original classification problem.
independently and identically distributed sample points drawn from the data sample space, one seeks to minimize empirical risk as a proxy for expected risk.
, i.e., the one that minimizes the expected risk associated with the zero-one loss, implements the Bayes optimal decision rule for a binary classification problem and is in the form of A loss function is said to be classification-calibrated or Bayes consistent if its optimal
by directly minimizing the expected risk and without having to explicitly model the probability density functions.
[6][1] Yet, this result does not exclude the existence of non-convex Bayes consistent loss functions.
A more general result states that Bayes consistent loss functions can be generated using the following formulation [7] where
Table-I shows the generated Bayes consistent loss functions for some example choices of
Such non-convex loss functions have been shown to be useful in dealing with outliers in classification.
, associated with the above generated loss functions can be directly found from equation (1) and shown to be equal to the corresponding
[9] Specifically a loss function of larger margin increases regularization and produces better estimates of the posterior probability.
It is shown that this is directly equivalent to decreasing the learning rate in gradient boosting
In conclusion, by choosing a loss function with larger margin (smaller
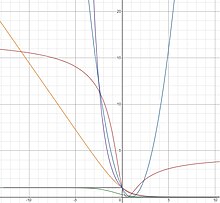
It can be generated using (2) and Table-I as follows The square loss function is both convex and smooth.
will perform poorly with the square loss function, since high values of
A benefit of the square loss function is that its structure lends itself to easy cross validation of regularization parameters.
The cross-entropy loss is ubiquitous in modern deep neural networks.
Interestingly, the Tangent loss also assigns a bounded penalty to data points that have been classified "too correctly".
The Tangent loss has been used in gradient boosting, the TangentBoost algorithm and Alternating Decision Forests.
The hinge loss provides a relatively tight, convex upper bound on the 0–1 indicator function.
In addition, the empirical risk minimization of this loss is equivalent to the classical formulation for support vector machines (SVMs).
[4] While the hinge loss function is both convex and continuous, it is not smooth (is not differentiable) at
[4] SVMs utilizing the hinge loss function can also be solved using quadratic programming.