Cycle detection
Several other algorithms trade off larger amounts of memory for fewer function evaluations.
The applications of cycle detection include testing the quality of pseudorandom number generators and cryptographic hash functions, computational number theory algorithms, detection of infinite loops in computer programs and periodic configurations in cellular automata, automated shape analysis of linked list data structures, and detection of deadlocks for transactions management in DBMS.
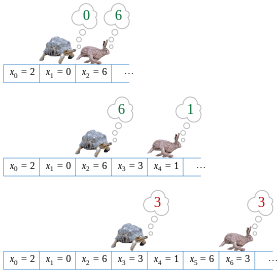
Let μ be the smallest index such that the value xμ reappears infinitely often within the sequence of values xi, and let λ (the loop length) be the smallest positive integer such that xμ = xλ + μ.
[1] One can view the same problem graph-theoretically, by constructing a functional graph (that is, a directed graph in which each vertex has a single outgoing edge) the vertices of which are the elements of S and the edges of which map an element to the corresponding function value, as shown in the figure.
The set of vertices reachable from starting vertex x0 form a subgraph with a shape resembling the Greek letter rho (ρ): a path of length μ from x0 to a cycle of λ vertices.
[1] They usually find lower and upper bounds μl ≤ μ ≤ μh for the start of the cycle, and a more detailed search of the range must be performed if the exact value of μ is needed.
(Continuing the search for an additional kλ/q steps, where q is the smallest prime divisor of kλ, will either find the true λ or prove that k = 1.)
Such a table implies O(|S|) space complexity, and if that is permissible, an associative array mapping xi to i will detect the first repeated value.
Rather, a cycle detection algorithm is given a black box for generating the sequence xi, and the task is to find λ and μ using very little memory.
The black box might consist of an implementation of the recurrence function f, but it might also store additional internal state to make the computation more efficient.
Although xi = f(xi−1) must be true in principle, this might be expensive to compute directly; the function could be defined in terms of the discrete logarithm of xi−1 or some other difficult-to-compute property which can only be practically computed in terms of additional information.
In such cases, the number of black boxes required becomes a figure of merit distinguishing the algorithms.
An associative array implementation requires computing a hash function on the elements of S, or ordering them.
This is done by computing the greatest common divisor of the difference xi − xi+λ with a known multiple of p, namely n. If the gcd is non-trivial (neither 1 nor n), then the value is a proper factor of n, as desired.
[2] If n is not prime, it must have at least one factor p ≤ √n, and by the birthday paradox, a random function f has an expected cycle length (modulo p) of √p ≤ 4√n.
However, the space complexity of this algorithm is proportional to λ + μ, unnecessarily large.
Additionally, to implement this method as a pointer algorithm would require applying the equality test to each pair of values, resulting in quadratic time overall.
The algorithm is named after Robert W. Floyd, who was credited with its invention by Donald Knuth.
[3][4] However, the algorithm does not appear in Floyd's published work, and this may be a misattribution: Floyd describes algorithms for listing all simple cycles in a directed graph in a 1967 paper,[5] but this paper does not describe the cycle-finding problem in functional graphs that is the subject of this article.
If there is a cycle, then, for any integers i ≥ μ and k ≥ 0, xi = xi + kλ, where λ is the length of the loop to be found, μ is the index of the first element of the cycle, and k is a whole integer representing the number of loops.
Thus, the algorithm only needs to check for repeated values of this special form, one twice as far from the start of the sequence as the other, to find a period ν of a repetition that is a multiple of λ.
[8] However, it is based on a different principle: searching for the smallest power of two 2i that is larger than both λ and μ.
For i = 0, 1, 2, ..., the algorithm compares x2i−1 with each subsequent sequence value up to the next power of two, stopping when it finds a match.
It has two advantages compared to the tortoise and hare algorithm: it finds the correct length λ of the cycle directly, rather than needing to search for it in a subsequent stage, and its steps involve only one evaluation of the function f rather than three.
It is not difficult to show that the number of function evaluations can never be higher than for Floyd's algorithm.
While Brent's algorithm uses a single tortoise, repositioned every time the hare passes a power of two, Gosper's algorithm uses several tortoises (several previous values are saved), which are roughly exponentially spaced.
According to the note in HAKMEM item 132,[11] this algorithm will detect repetition before the third occurrence of any value, i.e. the cycle will be iterated at most twice.
This is under the usual transdichotomous model, assumed throughout this article, in which the size of the function values is constant.
In order to do so quickly, they typically use a hash table or similar data structure for storing the previously-computed values, and therefore are not pointer algorithms: in particular, they usually cannot be applied to Pollard's rho algorithm.
Any cycle detection algorithm that stores at most M values from the input sequence must perform at least