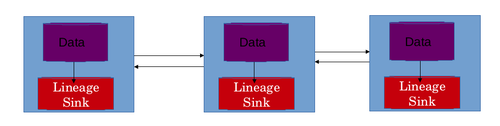
Data lineage
[1] It documents data's origins, transformations and movements, providing detailed visibility into its life cycle.
This process simplifies the identification of errors in data analytics workflows, by enabling users to trace issues back to their root causes.
"[3] Data governance plays a critical role in managing metadata by establishing guidelines, strategies and policies.
Data lineage visualization tools often include masking features that allow users to focus on information relevant to specific use cases.
The massive scale and unstructured nature of data, the complexity of these analytics pipelines, and long runtimes pose significant manageability and debugging challenges.
[11][12][13][14] As such, more cost-efficient ways of analyzing data intensive scale-able computing (DISC) are crucial to their continued effective use.
While these types of files may have an internal structure, they are still considered "unstructured" because the data they contain doesn't fit neatly into a database.
[18] In today's competitive business environment, companies have to find and analyze the relevant data they need quickly.
Some vendors are using increased memory and parallel processing to crunch large volumes of data quickly.
Even with this level of sophisticated hardware and software, a few of the image processing tasks in large scale take a few days to few weeks.
Integrating lineage across different granularities enables users to ask questions such as "Which file read by a MapReduce job produced this particular output record?"
[3] To capture end-to-end lineage in a DISC system, we use the Ibis model,[28] which introduces the notion of containment hierarchies for operators and data.
[27] Eager collection systems capture the entire lineage of the data flow at run time.
The kind of lineage they capture may be coarse-grain or fine-grain, but they do not require any further computations on the data flow after its execution.
[3] An actor is an entity that transforms data; it may be a Dryad vertex, individual map and reduce operators, a MapReduce job, or an entire dataflow pipeline.
The horizontal scaling feature of Big Data systems should be taken into account while creating the architecture of lineage store.
The architecture of Big Data systems makes use of a single lineage store not appropriate and impossible to scale.
[29] The information stored in terms of associations needs to be combined by some means to get the data flow of a particular job.
The directed graph created in the previous step is topologically sorted to obtain the order in which the actors have modified the data.
Another approach is to manually inspect lineage logs to find anomalies,[13][31] which can be tedious and time-consuming across several stages of a dataflow.
To debug analytics without known bad outputs, the data scientist needs to analyze the dataflow for suspicious behavior in general.
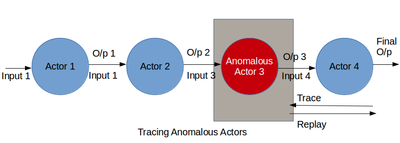
This section describes a debugging methodology for retrospectively analyzing lineage to identify faulty actors in a multi-stage dataflow.
that sudden changes in an actor's behavior, such as its average selectivity, processing rate or output size, is characteristic of an anomaly.
These challenges must be carefully evaluated in order to develop a realistic design for data lineage capture, taking into account the inherent trade-offs between them.
Lineage capture for these systems must be able scale to both large volumes of data and numerous operators to avoid being a bottleneck for the DISC analytics.
Current approaches to this include Prober, which seeks to find the minimal set of inputs that can produce a specified output for a black-box operator by replaying the dataflow several times to deduce the minimal set,[32] and dynamic slicing[33] to capture lineage for NoSQL operators through binary rewriting to compute dynamic slices.
Although producing highly accurate lineage, such techniques can incur significant time overheads for capture or tracing, and it may be preferable to instead trade some accuracy for better performance.
Replaying only specific inputs or portions of dataflow is crucial for efficient debugging and simulating what-if scenarios.
Ikeda et al. present a methodology for a lineage-based refresh, which selectively replays updated inputs to recompute affected outputs.
There is a need for an inexpensive automated debugging system, which can substantially narrow the set of potentially faulty operators, with reasonable accuracy, to minimize the amount of manual examination required.