Parallel computing
Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling.
Specialized parallel computer architectures are sometimes used alongside traditional processors, for accelerating specific tasks.
Communication and synchronization between the different subtasks are typically some of the greatest obstacles to getting optimal parallel program performance.
Maintaining everything else constant, increasing the clock frequency decreases the average time it takes to execute an instruction.
However, for a serial software program to take full advantage of the multi-core architecture the programmer needs to restructure and parallelize the code.
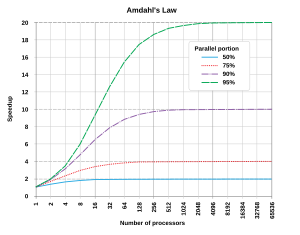
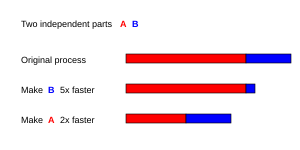
[14] Amdahl's Law indicates that optimal performance improvement is achieved by balancing enhancements to both parallelizable and non-parallelizable components of a task.
Furthermore, it reveals that increasing the number of processors yields diminishing returns, with negligible speedup gains beyond a certain point.
[15][16] Amdahl's Law has limitations, including assumptions of fixed workload, neglecting inter-process communication and synchronization overheads, primarily focusing on computational aspect and ignoring extrinsic factors such as data persistence, I/O operations, and memory access overheads.
According to David A. Patterson and John L. Hennessy, "Some machines are hybrids of these categories, of course, but this classic model has survived because it is simple, easy to understand, and gives a good first approximation.
"[34] Parallel computing can incur significant overhead in practice, primarily due to the costs associated with merging data from multiple processes.
Specifically, inter-process communication and synchronization can lead to overheads that are substantially higher—often by two or more orders of magnitude—compared to processing the same data on a single thread.
Parallel computer systems have difficulties with caches that may store the same value in more than one location, with the possibility of incorrect program execution.
Parallel computers based on interconnected networks need to have some kind of routing to enable the passing of messages between nodes that are not directly connected.
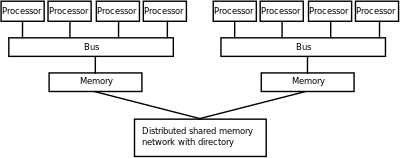
A symmetric multiprocessor (SMP) is a computer system with multiple identical processors that share memory and connect via a bus.
[52] As of 2014, most current supercomputers use some off-the-shelf standard network hardware, often Myrinet, InfiniBand, or Gigabit Ethernet.
Because of the low bandwidth and extremely high latency available on the Internet, distributed computing typically deals only with embarrassingly parallel problems.
[58] According to Michael R. D'Amour, Chief Operating Officer of DRC Computer Corporation, "when we first walked into AMD, they called us 'the socket stealers.'
[59] Computer graphics processing is a field dominated by data parallel operations—particularly linear algebra matrix operations.
The technology consortium Khronos Group has released the OpenCL specification, which is a framework for writing programs that execute across platforms consisting of CPUs and GPUs.
Meanwhile, performance increases in general-purpose computing over time (as described by Moore's law) tend to wipe out these gains in only one or two chip generations.
Fields as varied as bioinformatics (for protein folding and sequence analysis) and economics have taken advantage of parallel computing.
The origins of true (MIMD) parallelism go back to Luigi Federico Menabrea and his Sketch of the Analytic Engine Invented by Charles Babbage.
[72][73][74] In 1957, Compagnie des Machines Bull announced the first computer architecture specifically designed for parallelism, the Gamma 60.
[75] It utilized a fork-join model and a "Program Distributor" to dispatch and collect data to and from independent processing units connected to a central memory.
[78] Also in 1958, IBM researchers John Cocke and Daniel Slotnick discussed the use of parallelism in numerical calculations for the first time.
The motivation behind early SIMD computers was to amortize the gate delay of the processor's control unit over multiple instructions.
[79] His design was funded by the US Air Force, which was the earliest SIMD parallel-computing effort, ILLIAC IV.
[79] The key to its design was a fairly high parallelism, with up to 256 processors, which allowed the machine to work on large datasets in what would later be known as vector processing.
However, ILLIAC IV was called "the most infamous of supercomputers", because the project was only one-fourth completed, but took 11 years and cost almost four times the original estimate.
Minsky says that the biggest source of ideas about the theory came from his work in trying to create a machine that uses a robotic arm, a video camera, and a computer to build with children's blocks.