Data model
Managing large quantities of structured and unstructured data is a primary function of information systems.
[5] The reason for these problems is a lack of standards that will ensure that data models will both meet business needs and be consistent.
Early phases of many software development projects emphasize the design of a conceptual data model.
The next step in IS modeling was taken by CODASYL, an IT industry consortium formed in 1959, who essentially aimed at the same thing as Young and Kent: the development of "a proper structure for machine-independent problem definition language, at the system level of data processing".
[8] In the 1960s data modeling gained more significance with the initiation of the management information system (MIS) concept.
The first generation database system, called Integrated Data Store (IDS), was designed by Charles Bachman at General Electric.
[9] Towards the end of the 1960s, Edgar F. Codd worked out his theories of data arrangement, and proposed the relational model for database management based on first-order predicate logic.
However, it was Terry Halpin's 1989 PhD thesis that created the formal foundation on which Object–Role Modeling is based.
Bill Kent, in his 1978 book Data and Reality,[11] compared a data model to a map of a territory, emphasizing that in the real world, "highways are not painted red, rivers don't have county lines running down the middle, and you can't see contour lines on a mountain".
In contrast to other researchers who tried to create models that were mathematically clean and elegant, Kent emphasized the essential messiness of the real world, and the task of the data modeler to create order out of chaos without excessively distorting the truth.
"[12] During the early 1990s, three Dutch mathematicians Guido Bakema, Harm van der Lek, and JanPieter Zwart, continued the development on the work of G.M.
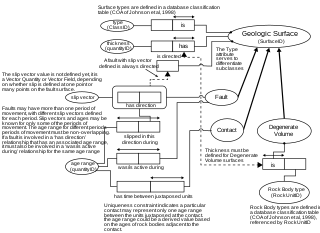
There are several styles for representing data structure diagrams, with the notable difference in the manner of defining cardinality.
There are several styles for representing data structure diagrams, with a notable difference in the manner of defining cardinality.
The modelers need to communicate and agree on certain elements that are to be rendered more concretely, in order to make the differences less significant.
A semantic data model is an abstraction that defines how the stored symbols relate to the real world.
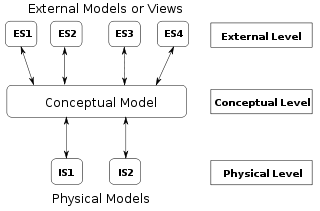
The logical data structure of a database management system (DBMS), whether hierarchical, network, or relational, cannot totally satisfy the requirements for a conceptual definition of data because it is limited in scope and biased toward the implementation strategy employed by the DBMS.
The real world, in terms of resources, ideas, events, etc., are symbolically defined within physical data stores.
A semantic data model is an abstraction that defines how the stored symbols relate to the real world.
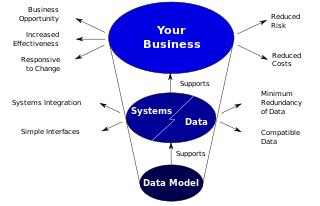
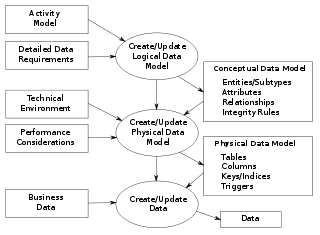
The data model will normally consist of entity types, attributes, relationships, integrity rules, and the definitions of those objects.
In that architecture, the physical model describes the storage media (cylinders, tracks, and tablespaces).
While data analysis is a common term for data modeling, the activity actually has more in common with the ideas and methods of synthesis (inferring general concepts from particular instances) than it does with analysis (identifying component concepts from more general ones).
A different approach is to use adaptive systems such as artificial neural networks that can autonomously create implicit models of data.
For example, a data model might include an entity class called "Person", representing all the people who interact with an organization.
Such an abstract entity class is typically more appropriate than ones called "Vendor" or "Employee", which identify specific roles played by those people.
It is common practice to draw a context-level data-flow diagram first which shows the interaction between the system and outside entities.
The DFD is designed to show how a system is divided into smaller portions and to highlight the flow of data between those parts.
Typically, they are used to model a constrained domain that can be described by a closed set of entity types, properties, relationships and operations.
According to Lee (1999)[21] an information model is a representation of concepts, relationships, constraints, rules, and operations to specify data semantics for a chosen domain of discourse.
Such object models are usually defined using concepts such as class, message, inheritance, polymorphism, and encapsulation.
To help ensure correctness, clarity, adaptability and productivity, information systems are best specified first at the conceptual level, using concepts and language that people can readily understand.