Depth-first search
Extra memory, usually a stack, is needed to keep track of the nodes discovered so far along a specified branch which helps in backtracking of the graph.
A version of depth-first search was investigated in the 19th century by French mathematician Charles Pierre Trémaux[1] as a strategy for solving mazes.
In theoretical computer science, DFS is typically used to traverse an entire graph, and takes time
For applications of DFS in relation to specific domains, such as searching for solutions in artificial intelligence or web-crawling, the graph to be traversed is often either too large to visit in its entirety or infinite (DFS may suffer from non-termination).
In such cases, search is only performed to a limited depth; due to limited resources, such as memory or disk space, one typically does not use data structures to keep track of the set of all previously visited vertices.
For such applications, DFS also lends itself much better to heuristic methods for choosing a likely-looking branch.
In the artificial intelligence mode of analysis, with a branching factor greater than one, iterative deepening increases the running time by only a constant factor over the case in which the correct depth limit is known due to the geometric growth of the number of nodes per level.
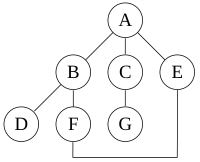
a depth-first search starting at the node A, assuming that the left edges in the shown graph are chosen before right edges, and assuming the search remembers previously visited nodes and will not repeat them (since this is a small graph), will visit the nodes in the following order: A, B, D, F, E, C, G. The edges traversed in this search form a Trémaux tree, a structure with important applications in graph theory.
It is also possible to use depth-first search to linearly order the vertices of a graph or tree.
For example, when searching the directed graph below beginning at node A, the sequence of traversals is either A B D B A C A or A C D C A B A (choosing to first visit B or C from A is up to the algorithm).
Note that repeat visits in the form of backtracking to a node, to check if it has still unvisited neighbors, are included here (even if it is found to have none).
This ordering is also useful in control-flow analysis as it often represents a natural linearization of the control flows.
The recursive implementation will visit the nodes from the example graph in the following order: A, B, D, F, E, C, G. The non-recursive implementation will visit the nodes as: A, E, F, B, D, C, G. The non-recursive implementation is similar to breadth-first search but differs from it in two ways: If G is a tree, replacing the queue of the breadth-first search algorithm with a stack will yield a depth-first search algorithm.
[8] Algorithms that use depth-first search as a building block include: The computational complexity of DFS was investigated by John Reif.
John Reif considered the complexity of computing the lexicographic depth-first search ordering, given a graph and a source.
[13]: 189 A depth-first search ordering (not necessarily the lexicographic one), can be computed by a randomized parallel algorithm in the complexity class RNC.
[14] As of 1997, it remained unknown whether a depth-first traversal could be constructed by a deterministic parallel algorithm, in the complexity class NC.