Parallel breadth-first search
For instance, BFS is used by Dinic's algorithm to find maximum flow in a graph.
As a simple and intuitive solution, the classic Parallel Random Access Machine (PRAM) approach is just an extension of the sequential algorithm that is shown above.
Secondly, in spite of the speedup of each layer-traversal due to parallel processing, a barrier synchronization is needed after every layer in order to completely discover all neighbor vertices in the frontier.
This layer-by-layer synchronization indicates that the steps of needed communication equals the longest distance between two vertices, O(d), where O is the big O notation and d is the graph diameter.
As a result, it is very important to make the parallel BFS on shared memory load-balanced.
Alternatively, they can be global to provide implicit load balancing, where special data structures are used for concurrent access from processing entities.
Moreover, the reducer can be combined with the bag-structure to write vertices in parallel and traverse them efficiently.
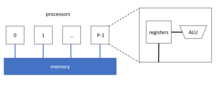
Because of this, processing entities must send and receive messages to each other to share its local data or get access to remote data.1D partitioning is the simplest way to combine the parallel BFS with distributed memory.
Load balancing is still an important issue for data partition, which determines how we can benefit from parallelization.
For the implementation of data storage, each processor can store an adjacency matrix of its local vertices, in which each row for each vertex is a row of outgoing edges represented by destination vertex indices.
The following pseudo-code of a 1-D distributed memory BFS[5] was originally designed for IBM BlueGene/L systems, which have a 3D torus network architecture.
After that, they also reduced the number of point-to-point communication, taking advantage of its high-bandwidth torus network.
The main steps of BFS traversal in the following algorithm are: Combined with multi-threading, the following pseudo code of 1D distributed memory BFS also specifies thread stack and thread barrier, which comes from the paper.
[6] With multi-threading, local vertices in the frontier FS can be divided and assigned to different threads inside of one processor, which further parallel the BFS traversal.
As a result, although distributed memory with multi-threading might benefit from refinement of parallelization, it also introduces extra synchronization cost for threads.
The edges and vertices are assigned to all processors with 2D block decomposition, in which the sub-adjacency matrix is stored.
If there are in total P=R·C processors, then the adjacency matrix will be divided like below: There are C columns and R·C block rows after this division.
After this communication, each processor can traverse the column of according to the vertices and find out their neighbors to form the next frontier.
[5] The main steps of BFS traversal in this 2D partitioning algorithm are(for each processor): The pseudo-code below describes more details of 2D BFS algorithm, which comes from the paper:[5] In 2D partitioning, only columns or rows of processors participate in communication in "expand" or "fold" phase respectively.
Besides, 2D partitioning is also more flexible for better load balancing, which makes a more scalable and storage-efficient approach much easier.
Even better is that, each vertex would quickly find a parent by checking its incoming edges if a significant number of its neighbors are in the frontier.
In the paper,[8] the authors introduce a bottom-up BFS where each vertex only needs to check whether any of their parents is in the frontier.
For instance, in paper,[6] the graph is traversed by randomly shuffling all vertex identifiers prior to partitioning.
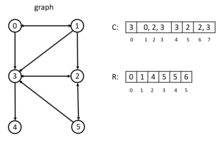
There are some special data structures that parallel BFS can benefit from, such as CSR (Compressed Sparse Row), bag-structure, bitmap and so on.
Array R stored the index in C, the entry R[i] points to the beginning index of adjacency lists of vertex i in array C. The CSR is extremely fast because it costs only constant time to access vertex adjacency.
[9] For 2D partitioning, DCSC (Doubly Compressed Sparse Columns) for hyper-sparse matrices is more suitable.
[4] Moreover, bitmap is also a very useful data structure to memorize which vertices are already visited, regardless in the bottom-up BFS.
[11] or just to check if vertices are visited in the top-down BFS[9] Graph500 is the first benchmark for data-intensive supercomputing problems.
In the referenced BFS, the exploration of vertices is simply sending messages to target processors to inform them of visited neighbors.
For the synchronization, AML (Active Messages Library, which is an SPMD communication library build on top of MPI3, intend to be used in fine grain applications like Graph500) barrier ensures the consistent traversal after each layer.