Expectation–maximization algorithm
In statistics, an expectation–maximization (EM) algorithm is an iterative method to find (local) maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables.
[2] The EM algorithm was explained and given its name in a classic 1977 paper by Arthur Dempster, Nan Laird, and Donald Rubin.
[10][11][12][13][14] The Dempster–Laird–Rubin paper in 1977 generalized the method and sketched a convergence analysis for a wider class of problems.
The Dempster–Laird–Rubin paper established the EM method as an important tool of statistical analysis.
[15] Wu's proof established the EM method's convergence also outside of the exponential family, as claimed by Dempster–Laird–Rubin.
[15] The EM algorithm is used to find (local) maximum likelihood parameters of a statistical model in cases where the equations cannot be solved directly.
Typically these models involve latent variables in addition to unknown parameters and known data observations.
Finding a maximum likelihood solution typically requires taking the derivatives of the likelihood function with respect to all the unknown values, the parameters and the latent variables, and simultaneously solving the resulting equations.
The EM algorithm proceeds from the observation that there is a way to solve these two sets of equations numerically.
as a latent variable indicating membership in one of a set of groups: However, it is possible to apply EM to other sorts of models.
are unknown: The algorithm as just described monotonically approaches a local minimum of the cost function.
For multimodal distributions, this means that an EM algorithm may converge to a local maximum of the observed data likelihood function, depending on starting values.
A variety of heuristic or metaheuristic approaches exist to escape a local maximum, such as random-restart hill climbing (starting with several different random initial estimates
[8][9][11][12][13][14] The EM method was modified to compute maximum a posteriori (MAP) estimates for Bayesian inference in the original paper by Dempster, Laird, and Rubin.
Unlike EM, such methods typically require the evaluation of first and/or second derivatives of the likelihood function.
The EM algorithm can be viewed as two alternating maximization steps, that is, as an example of coordinate descent.
EM algorithms can be used for solving joint state and parameter estimation problems.
Filtering and smoothing EM algorithms arise by repeating this two-step procedure: Suppose that a Kalman filter or minimum-variance smoother operates on measurements of a single-input-single-output system that possess additive white noise.
An updated measurement noise variance estimate can be obtained from the maximum likelihood calculation where
Parameter-expanded expectation maximization (PX-EM) algorithm often provides speed up by "us[ing] a `covariance adjustment' to correct the analysis of the M step, capitalising on extra information captured in the imputed complete data".
A fully Bayesian version of this may be wanted, giving a probability distribution over θ and the latent variables.
If using the factorized Q approximation as described above (variational Bayes), solving can iterate over each latent variable (now including θ) and optimize them one at a time.
For graphical models this is easy to do as each variable's new Q depends only on its Markov blanket, so local message passing can be used for efficient inference.
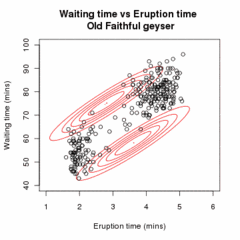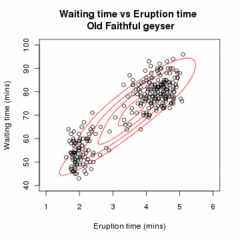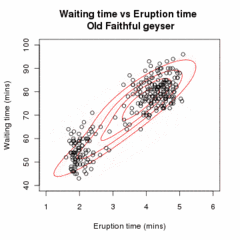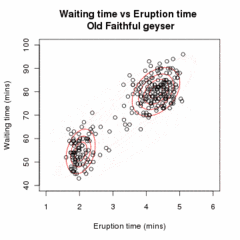
Given our current estimate of the parameters θ(t), the conditional distribution of the Zi is determined by Bayes theorem to be the proportional height of the normal density weighted by τ: These are called the "membership probabilities", which are normally considered the output of the E step (although this is not the Q function of below).
This full conditional expectation does not need to be calculated in one step, because τ and μ/Σ appear in separate linear terms and can thus be maximized independently.
: This has the same form as a weighted maximum likelihood estimate for a normal distribution, so and, by symmetry, Conclude the iterative process if
[38] Special cases of this model include censored or truncated observations from one normal distribution.
Alternatives to EM exist with better guarantees for consistency, which are termed moment-based approaches[39] or the so-called spectral techniques.
[40][41] Moment-based approaches to learning the parameters of a probabilistic model enjoy guarantees such as global convergence under certain conditions unlike EM which is often plagued by the issue of getting stuck in local optima.
For these spectral methods, no spurious local optima occur, and the true parameters can be consistently estimated under some regularity conditions.