HMAC
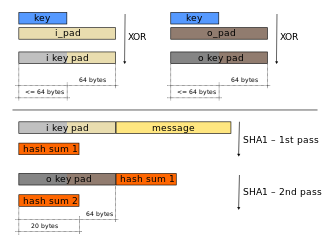
The second pass produces the final HMAC code derived from the inner hash result and the outer key.
The size of the output of HMAC is the same as that of the underlying hash function (e.g., 256 and 512 bits in the case of SHA-256 and SHA3-512, respectively), although it can be truncated if desired.
The definition and analysis of the HMAC construction was first published in 1996 in a paper by Mihir Bellare, Ran Canetti, and Hugo Krawczyk,[1][2] and they also wrote RFC 2104 in 1997.
[3]: §2 The design of the HMAC specification was motivated by the existence of attacks on more trivial mechanisms for combining a key with a hash function.
However, this method suffers from a serious flaw: with most hash functions, it is easy to append data to the message without knowing the key and obtain another valid MAC ("length-extension attack").
The values of ipad and opad are not critical to the security of the algorithm, but were defined in such a way to have a large Hamming distance from each other and so the inner and outer keys will have fewer bits in common.
[9] The cryptographic strength of the HMAC depends upon the size of the secret key that is used and the security of the underlying hash function used.
[14][15][16] In 2006, Jongsung Kim, Alex Biryukov, Bart Preneel, and Seokhie Hong showed how to distinguish HMAC with reduced versions of MD5 and SHA-1 or full versions of HAVAL, MD4, and SHA-0 from a random function or HMAC with a random function.
For HMAC-MD5 the RFC summarizes that – although the security of the MD5 hash function itself is severely compromised – the currently known "attacks on HMAC-MD5 do not seem to indicate a practical vulnerability when used as a message authentication code", but it also adds that "for a new protocol design, a ciphersuite with HMAC-MD5 should not be included".
[13] In May 2011, RFC 6234 was published detailing the abstract theory and source code for SHA-based HMACs.