Low-discrepancy sequence
Specific definitions of discrepancy differ regarding the choice of B (hyperspheres, hypercubes, etc.)
and how the discrepancy for every B is computed (usually normalized) and combined (usually by taking the worst value).
The "quasi" modifier is used to denote more clearly that the values of a low-discrepancy sequence are neither random nor pseudorandom, but such sequences share some properties of random variables and in certain applications such as the quasi-Monte Carlo method their lower discrepancy is an important advantage.
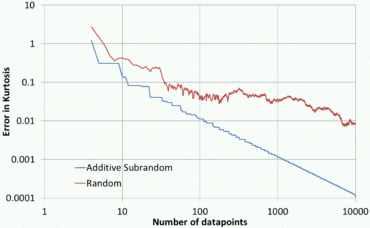
Quasirandom numbers allow higher-order moments to be calculated to high accuracy very quickly.
Applications that don't involve sorting would be in finding the mean, standard deviation, skewness and kurtosis of a statistical distribution, and in finding the integral and global maxima and minima of difficult deterministic functions.
Quasirandom numbers can also be used for providing starting points for deterministic algorithms that only work locally, such as Newton–Raphson iteration.
With a search algorithm, quasirandom numbers can be used to find the mode, median, confidence intervals and cumulative distribution of a statistical distribution, and all local minima and all solutions of deterministic functions.
If the points are chosen to be randomly (or pseudorandomly) distributed, this is the Monte Carlo method.
If the points are chosen as elements of a low-discrepancy sequence, this is the quasi-Monte Carlo method.
A remarkable result, the Koksma–Hlawka inequality (stated below), shows that the error of such a method can be bounded by the product of two terms, one of which depends only on
The rectangle rule uses points set which have low discrepancy, but in general the elements must be recomputed if
Elements need not be recomputed in the random Monte Carlo method if
The two are related by Note: With these definitions, discrepancy represents the worst-case or maximum point density deviation of a uniform set.
-discrepancy are also used intensively to compare the quality of uniform point sets.
such that Therefore, the quality of a numerical integration rule depends only on the discrepancy
discrepancy has a high practical importance because fast explicit calculations are possible for a given point set.
It is computationally hard to find the exact value of the discrepancy of large point sets.
The best-known lower bounds are due to Michael Lacey and collaborators.
Jozef Beck [1] established a double log improvement of this result in three dimensions.
One general limitation is that construction methods can usually only guarantee the order of convergence.
points from a low-discrepancy sequence generator may offer only a very minor accuracy improvement [citation needed].
gives lower discrepancy than a sequence of independent uniform random numbers.
A convenient set of values that are used, is the square roots of primes from two up, all taken modulo 1: However, a set of values based on the generalised golden ratio has been shown to produce more evenly distributed points.
Note: In few dimensions, recursive recurrence leads to uniform sets of good quality, but for larger
Note: The formulas show that the Hammersley set is actually the Halton sequence, but we get one more dimension for free by adding a linear sweep.
, most low-discrepancy point set generators deliver at least near-optimum discrepancies.
The Antonov–Saleev variant of the Sobol’ sequence generates numbers between zero and one directly as binary fractions of length
take the exclusive or of the binary value of the Gray code of
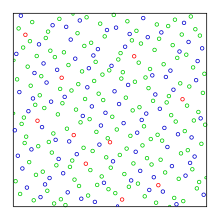
Poisson disk sampling is popular in video games to rapidly place objects in a way that appears random-looking but guarantees that every two points are separated by at least the specified minimum distance.
For comparison, 10000 elements of a sequence of pseudorandom points are also shown.