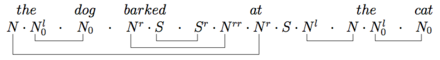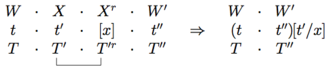Pregroup grammar
Much like categorial grammar (CG), PG is a kind of type logical grammar.
Unlike CG, however, PG does not have a distinguished function type.
Rather, PG uses inverse types combined with its monoidal operation.
A pregroup is a partially ordered algebra
is a monoid, satisfying the following relations: The contraction and expansion relations are sometimes called Ajdukiewicz laws.
are called the left and right adjoints of x, respectively.
A pregroup grammar consists of a lexicon of words (and possibly morphemes) L, a set of atomic types T which freely generates a pregroup, and a relation
In simple pregroup grammars, typing is a function that maps words to only one type each.
Some simple, intuitive examples using English as the language to model demonstrate the core principles behind pregroups and their use in linguistic domains.
Let L = {John, Mary, the, dog, cat, met, barked, at}, let T = {N, S, N0}, and let the following typing relation hold: A sentence S that has type T is said to be grammatical if
{\displaystyle {\textit {John}}\ {\textit {met}}\ {\textit {Mary}}:N\cdot N^{r}\cdot S\cdot N^{l}\cdot N}
A more convenient notation exists, however, that indicates contractions by connecting them with a drawn link between the contracting types (provided that the links are nested, i.e. don't cross).
Words are also typically placed above their types to make the proof more intuitive.
The same proof in this notation is simply A more complex example proves that the dog barked at the cat is grammatical: Pregroup grammars were introduced by Joachim Lambek in 1993 as a development of his syntactic calculus, replacing the quotients by adjoints.
Adding such adjoints was interesting to handle more complex linguistic cases, where the fact that
It was also motivated by a more algebraic viewpoint: the definition of a pregroup is a weakening of that of a group, introducing a distinction between the left and right inverses and replacing the equality by an order.
This weakening was needed because using types from a free group would not work: an adjective would get the type
, hence it could be inserted at any position in the sentence.
[4] Pregroup grammars have then been defined and studied for various languages (or fragments of them) including English,[5] Italian,[6] French,[7] Persian[8] and Sanskrit.
[9] Languages with a relatively free word order such as Sanskrit required to introduce commutation relations to the pregroup, using precyclicity.
Because of the lack of function types in PG, the usual method of giving a semantics via the λ-calculus or via function denotations is not available in any obvious way.
Instead, two different methods exist, one purely formal method that corresponds to the λ-calculus, and one denotational method analogous to (a fragment of) the tensor mathematics of quantum mechanics.
The purely formal semantics for PG consists of a logical language defined according to the following rules: Some examples of terms are f(x), g(a,h(x,y)),
The usual conventions regarding α conversion apply.
For a given language, we give an assignment I that maps typed words to typed closed terms in a way that respects the pregroup structure of the types.
For the English fragment given above we might therefore have the following assignment (with the obvious, implicit set of atomic terms and function symbols): where E is the type of entities in the domain, and T is the type of truth values.
Together with this core definition of the semantics of PG, we also have a reduction rules that are employed in parallel with the type reductions.
Placing the syntactic types at the top and semantics below, we have For example, applying this to the types and semantics for the sentence
(emphasizing the link being reduced) For the sentence
{\displaystyle {\textit {the}}\ {\textit {dog}}\ {\textit {barked}}\ {\textit {at}}\ {\textit {the}}\ {\textit {cat}}:(N\cdot N_{0}^{l})\cdot N_{0}\cdot (N^{r}\cdot S)\cdot (S^{r}\cdot N^{rr}\cdot N^{r}\cdot S\cdot N^{l})\cdot (N\cdot N_{0}^{l})\cdot N_{0}}