Ray casting
The term "Ray Casting" was introduced by Scott Roth while at the General Motors Research Labs from 1978–1980.
This eliminates the possibility of accurately rendering reflections, refractions, or the natural falloff of shadows; however all of these elements can be faked to a degree, by creative use of texture maps or other methods.
The high speed of calculation made ray casting a handy rendering method in early real-time 3D video games.
Using the material properties and the effect of the lights in the scene, this algorithm can determine the shading of this object.
One important advantage ray casting offered over older scanline algorithms was its ability to easily deal with non-planar surfaces and solids, such as cones and spheres.
Although the perspective view is natural for making pictures, some applications need rays that can be uniformly distributed in space.
For modeling convenience, a typical standard coordinate system for the camera has the screen in the X–Y plane, the scene in the +Z half space, and the focal point on the −Z axis.
The vector can be normalized easily with the following computation: Given geometric definitions of the objects, each bounded by one or more surfaces, the result of computing one ray’s intersection with all bounded surfaces in the screen is defined by two arrays: Where n is the number of ray-surface intersections.
This could be useful, for instance, when an object consists of an assembly of different materials and the overall center of mass and moments of inertia are of interest.
To draw the visible edges of a solid, generate one ray per pixel moving top-down, left-right in the screen.
For each picture, the screen was sampled with a density of about 100×100 (e.g., 10,000) rays and new edges were located via binary searches.
The pixel’s value, the displayable light intensity, is proportional to the cosine of the angle formed by the surface normal and the light-source-to-surface vector.
This is a use of parallel-projection camera model.This figure shows an example of the binary operators in a composition tree using “+” and “−” where a single ray is evaluated.
The ray casting procedure starts at the top of the solid composition tree, recursively descends to the bottom, classifies the ray with respect to the primitive solids, and then returns up the tree combining the classifications of the left and right subtrees.
The grayscale ray-casting system developed by Scott Roth and Daniel Bass at GM Research Labs produced pictures on a Ramtek color raster display around 1979.
To compose pictures, the system provided the user with the following controls: This figure shows a table scene with shadows from two point light sources.
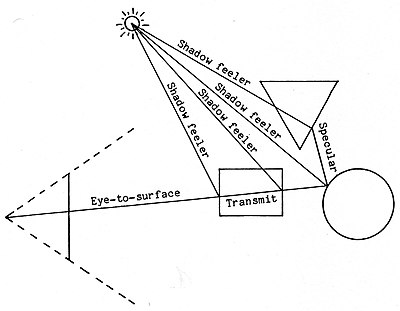
For example, the following figure shows the additional rays that could be cast for a single light source.For a single pixel in the image to be rendered, the algorithm casts a ray starting at the focal point and determines that it intersects a semi-transparent rectangle and a shiny circle.
The “Shadow feeler” ray is cast from the ray-surface intersection point to the light source to determine if any other surface blocks that pathway.
But all position, shape, and size information is stored at the leaves of the tree where primitive solids reside.
Characterizing with enclosures the space that all solids fill gives all nodes in the tree an abstract summary of position and size information.
When the test fails at an intermediate node in the tree, the ray is guaranteed to classify as out of the composite, so recursing down its subtrees to further investigate is unnecessary.
The jagged edges caused by aliasing is an undesirable effect of point sampling techniques and is a classic problem with raster display algorithms.
The purpose of such an algorithm is to minimize the number of lines needed to draw the picture within one pixel accuracy.
In early first person games, raycasting was used to efficiently render a 3D world from a 2D playing field using a simple one-dimensional scan over the horizontal width of the screen.
[7] Early first-person shooters used 2D ray casting as a technique to create a 3D effect from a 2D world.
[7][8] This style of rendering eliminates the need to fire a ray for each pixel in the frame as is the case with modern engines; once the hit point is found the projection distortion is applied to the surface texture and an entire vertical column is copied from the result into the frame.
The video game Wolfenstein 3D was built from a square based grid of uniform height walls meeting solid-colored floors and ceilings.
[9] The purpose of the grid based levels was twofold — ray-wall collisions can be found more quickly since the potential hits become more predictable and memory overhead is reduced.
The Raven Software game ShadowCaster uses an improved Wolfenstein-based engine with added floors and ceilings texturing and variable wall heights.
The problem has been investigated for various settings: space dimension, types of objects, restrictions on query rays, etc.