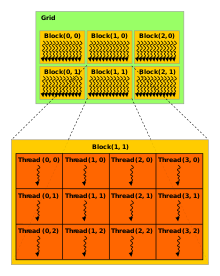
Thread block (CUDA programming)
The number of threads in a block is limited, but grids can be used for computations that require a large number of thread blocks to operate in parallel and to use all available multiprocessors.
Every thread has an index, which is used for calculating memory address locations and also for taking control decisions.
In this model, we start executing an application on the host device which is usually a CPU core.
Every thread in CUDA is associated with a particular index so that it can calculate and access memory locations in an array.
One of the organization structure is taking a grid with a single block that has a 512 threads.
If we want to consider computations for an array that is larger than 1024 we can have multiple blocks with 1024 threads each.
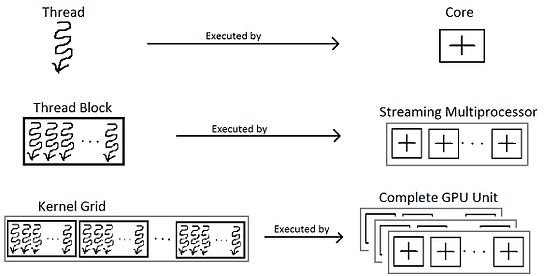
In order to get a complete gist of thread block, it is critical to know it from a hardware perspective.
Several thread blocks are assigned to a Streaming Multiprocessor (SM).
Several SM constitute the whole GPU unit (which executes the whole Kernel Grid).
[citation needed] Each architecture in GPU (say Kepler or Fermi) consists of several SM or Streaming Multiprocessors.
These are general purpose processors with a low clock rate target and a small cache.
In general, SMs support instruction-level parallelism but not branch prediction.
In general an SM can handle multiple thread blocks at the same time.
Each thread block is divided in scheduled units known as a warp.
On the hardware side, a thread block is composed of ‘warps’.
[13] Once a thread block is launched on a multiprocessor (SM), all of its warps are resident until their execution finishes.
If one or both of its operands are not ready (e.g. have not yet been fetched from global memory), a process called ‘context switching’ takes place which transfers control to another warp.
Different policies for scheduling warps that are eligible for execution are discussed below:[15] Traditional CPU thread context "switching" requires saving and restoring allocated register values and the program counter to off-chip memory (or cache) and is therefore a much more heavyweight operation than with warp context switching.
All of a warp's register values (including its program counter) remain in the register file, and the shared memory (and cache) remain in place too since these are shared between all the warps in the thread block.
In order to take advantage of the warp architecture, programming languages and developers need to understand how to coalesce memory accesses and how to manage control flow divergence.
If each thread in a warp takes a different execution path or if each thread accesses significantly divergent memory then the benefits of the warp architecture are lost and performance will significantly degrade.