3D sound localization
Most mammals (including humans) use binaural hearing to localize sound, by comparing the information received from each ear in a complex process that involves a significant amount of synthesis.
Sound localization technology is used in some audio and acoustics fields, such as hearing aids, surveillance[1] and navigation.
For instance: This approach utilizes eight microphones combined with a steered beamformer enhanced by the Reliability Weighted Phase Transform (RWPHAT).
Exploiting this extra information, AVS arrays are able to significantly improve the accuracy of source localization.
• Can be used in combination with the Offline Calibration Process[11] to measure and interpolate the impulse response of X, Y, Z and O arrays, to obtain their steering vector.
The advantages of this array, compared with past microphone array, are that this device has a high performance even if the aperture is small, and it can localize multiple low frequency and high frequency wide band sound sources simultaneously.
Scan-based techniques are a powerful tool for localizing and visualizing time-stationary sound sources, as they only require the use of a single sensor and a position tracking system.
One popular method for achieving this is through the use of an Acoustic Vector Sensor (AVS), also known as a 3D Sound Intensity Probe, in combination with a 3D tracker.
The recorded signals are then split into multiple segments and assigned to a set of positions using a spatial discretization algorithm.
The system makes use of a learning process using neural networks by rotating the head with a settled white noise sound source and analyzing the spectrum.
Experiments show that the system can identify the direction of the source well in a certain range of angle of arrival.
It cannot identify the sound coming outside the range due to the collapsed spectrum pattern of the reflector.
In the real sound localization, the robot head and the torso play a functional role, in addition to the two pinnae.
Instead of using the neural networks, a head-related transfer function is used and the localization is based on a simple correlation approach.
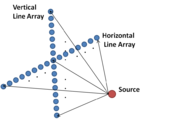
In order to estimate the location of a source in 3D space, two line sensor arrays can be placed horizontally and vertically.
[16] By processing the data from two arrays using the maximum likelihood method, the direction, range and depth of the source can be identified simultaneously.
The phase shift of the resulting sinusoidal signal can be directly mapped to the azimuth angle of the sound source, and the amplitude of the ICTD signal can be represented as a function of the elevation angle of the sound source and the distance between the two microphones.
Machine learning techniques such as Random sample consensus (RANSAC) and Density-based spatial clustering of applications with noise (DBSCAN) can be applied to identify phase shifts (mapping to azimuths) and amplitudes (mapping to elevations) of each discontinuous sinusoidal waveform in the ICTD signal.
Some animals experience difficulty in 3D sound location due to small head size.
Additionally, the wavelength of communication sound may be much larger than their head diameter, as is the case with frogs.
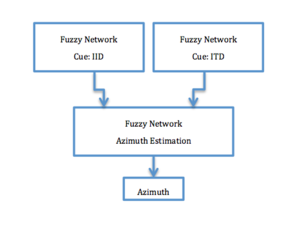
Based on previous binaural sound localization methods, a hierarchical fuzzy artificial neural network system combines interaural time difference(ITD-based) and interaural intensity difference(IID-based) sound localization methods for higher accuracy that is similar to that of humans.
Hierarchical Fuzzy Artificial Neural Networks[20] were used with the goal of the same sound localization accuracy as human ears.
IID-based or ITD-based sound localization methods have a main problem called Front-back confusion.
If the array is too small, then the microphones are spaced too closely together so that they all record essentially the same sound (with ITF near zero), making it extremely difficult to estimate the orientation.
The disadvantage of this method is that many parametric operations are necessary for the whole set of filters to realize the 3D sound localization, resulting in high computational complexity.
A DSP-based implementation of a realtime 3D sound localization approach with the use of an embedded DSP can reduce the computational complexity As shown in the figure, the implementation procedure of this realtime algorithm is divided into three phases, (i) Frequency Division, (ii) Sound Localization, and (iii) Mixing.
Monaural localization is made possible by the structure of the pinna (outer ear), which modifies the sound in a way that is dependent on its incident angle.
A machine learning approach is adapted for monaural localization using only a single microphone and an “artificial pinna” (that distorts sound in a direction-dependent way).
[23] The experimental results also show that the algorithm is able to fairly accurately localize a wide range of sounds, such as human speech, dog barking, waterfall, thunder, and so on.
In contrast to microphone arrays, this approach also offers the potential of significantly more compact, as well as lower cost and power, devices for sound localization.